进阶——基于VPP编排的灵活模型层分配策略研发
1.研究当前是否支持灵活模型层分配
hidden_layer=8,layer_to_mesh=[mesh0,mesh0,mesh0,mesh0,mesh0,mesh1,mesh1,mesh1](即0设备5层,1设备3层)
没报错,但是假灵活分配:

即仍然按照设备0放4层,设备1放4层
2.改进策略
研究现有的函数发现,有一个分析是否使用用户的分配,根据该函数可以改写,提取到用户的layer_to_mesh,即用户将每层放在哪个设备上的意图,从而提取到,用户对每个设备分配的layer数。
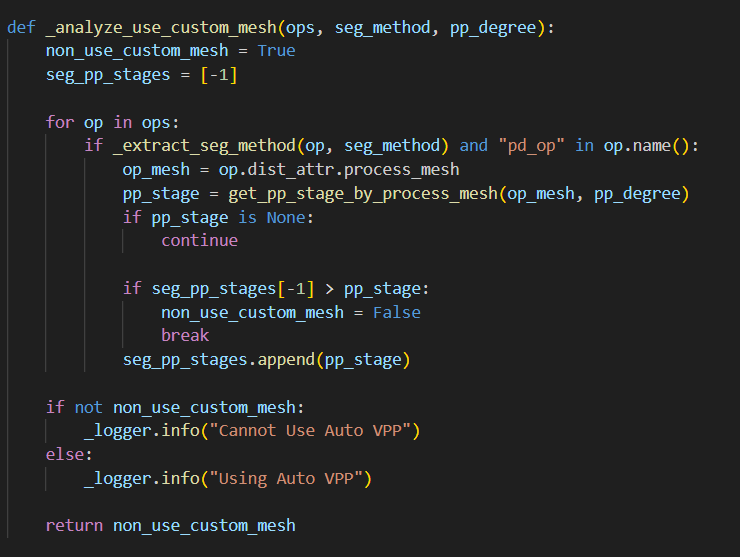
改写代码如下,获得用户将模型层分配在各设备的意图:
last_struct_name=None
user_layer_to_stage_id=[]
for idx, op in enumerate(ops):
if len(seg_parts) == len(seg_struct_names):
break
struct_name = _extract_seg_method(op, seg_method)#每个属于该struct_name的op都会有这个属性名,用来查看当前op属于哪一层
if op.dist_attr is not None and last_struct_name!=struct_name:
if get_pp_stage_by_process_mesh(op.dist_attr.process_mesh,pp_degree)!=None:
user_layer_to_stage_id.append(get_pp_stage_by_process_mesh(op.dist_attr.process_mesh,pp_degree))
last_struct_name=struct_name
if struct_name == seg_struct_names[len(seg_parts)]:
seg_parts.append(idx)#统计每个 struct_name 最开始的op的index,可以统计出起始和终止位置
seg_parts.append(len(ops))#最后一个层的op截至位置为最后一个op
pp_stage_layer_num=[0]*pp_degree#存放各设备分配的块数
for i in user_layer_to_stage_id:#获取用户意图,即各设备的分配情况
pp_stage_layer_num[i]=pp_stage_layer_num[i]+1
按照以下思想来确定:
assert all(value >= vpp_degree for value in pp_stage_layer_num)#每个设备上层数至少等于块数,块不能为空
seg_layer_num=[0]*num_chunks#记录每个块里面的层数
for pp_stage in range(0,pp_degree):
pp_stage_layer_nums=pp_stage_layer_num[pp_stage]
for i in range(0,pp_stage_layer_nums):
v_chunk_id=i % vpp_degree #0开始
r_chunk_id=(v_chunk_id)*pp_degree+pp_stage#-1和+1抵消了
seg_layer_num[r_chunk_id]=seg_layer_num[r_chunk_id]+1 #块里面的层数+1
最终效果:
