DualPipe学习记录
Deepseek V3选择仍使用ZeRO-1
采用了16路管道并行和64路专家并行
1.Zero Bubble Pipeline Parallelism
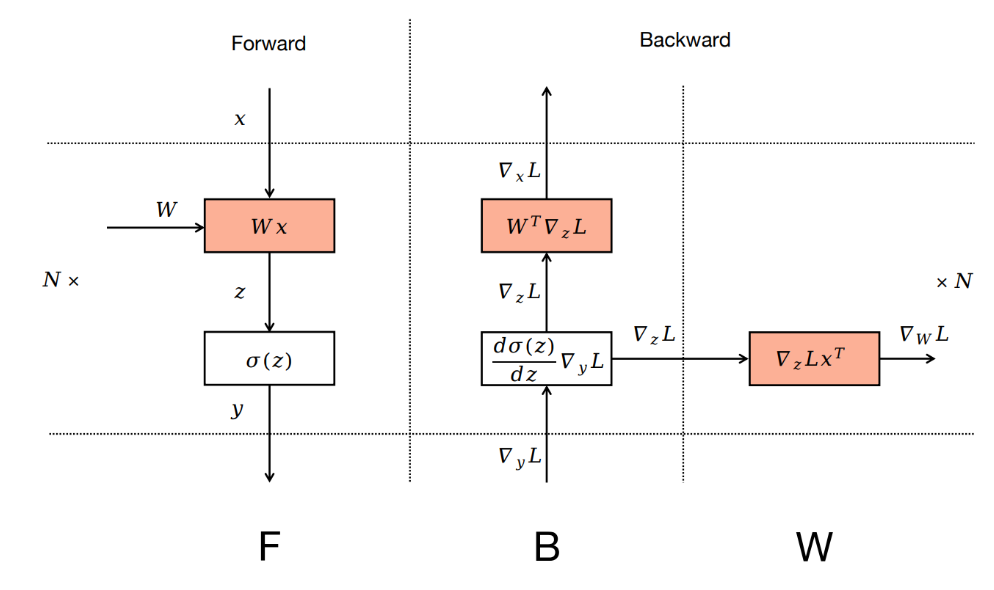
这里B是做梯度计算,W是做梯度更新,往常来说,是所有backward做完,才一次性做所有的参数更新,分开后,即一个b一个w
ZeRO-1即使用的zero_bubble策略
ZB1(上图)即峰值显存约为4个micro_batch,ZB2(下图)即峰值显存增加为8个micro_batch
2.专家并行
在MoE(mixture of expert)网络中,包含expert部分,门控网络,以及all to all操作,
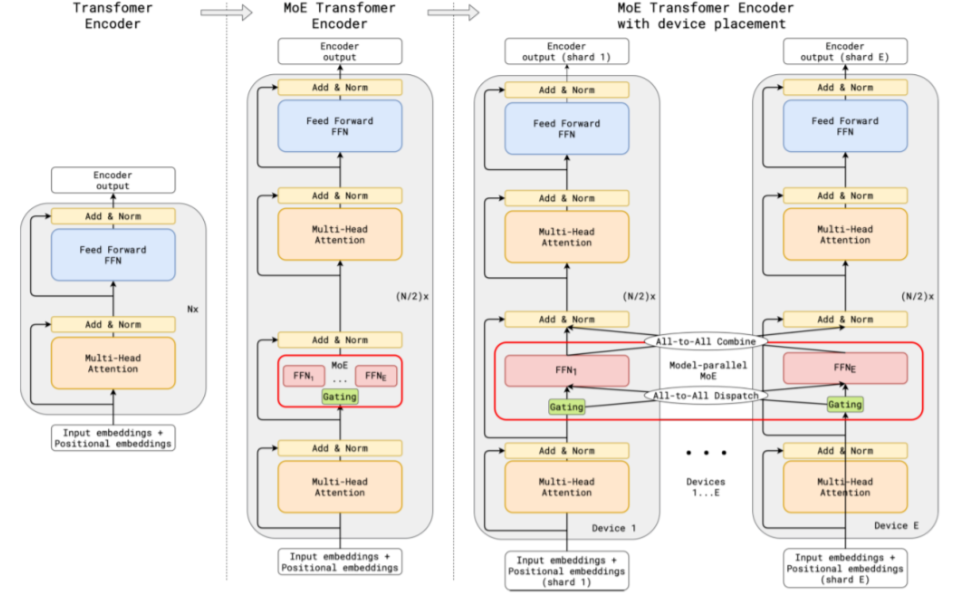
3.Deepseek-v3中的模型层
3.1 基础模型结构
RMSNorm为均方根标准化,公式如3.1所示,其中RMS(x)如公式3.2所示,γ为可学习参数。FFN即为DeepSeekMoE,Attention部分,即为MLA。 $$ y=\frac{x}{\mathrm{RMS}(x)}\odot\gamma $$ 公式3.1 $$ \mathrm{RMS}(x)=\sqrt{\frac{1}{n}\sum_{i=1}^nx_i^2+\epsilon} $$ 公式3.2
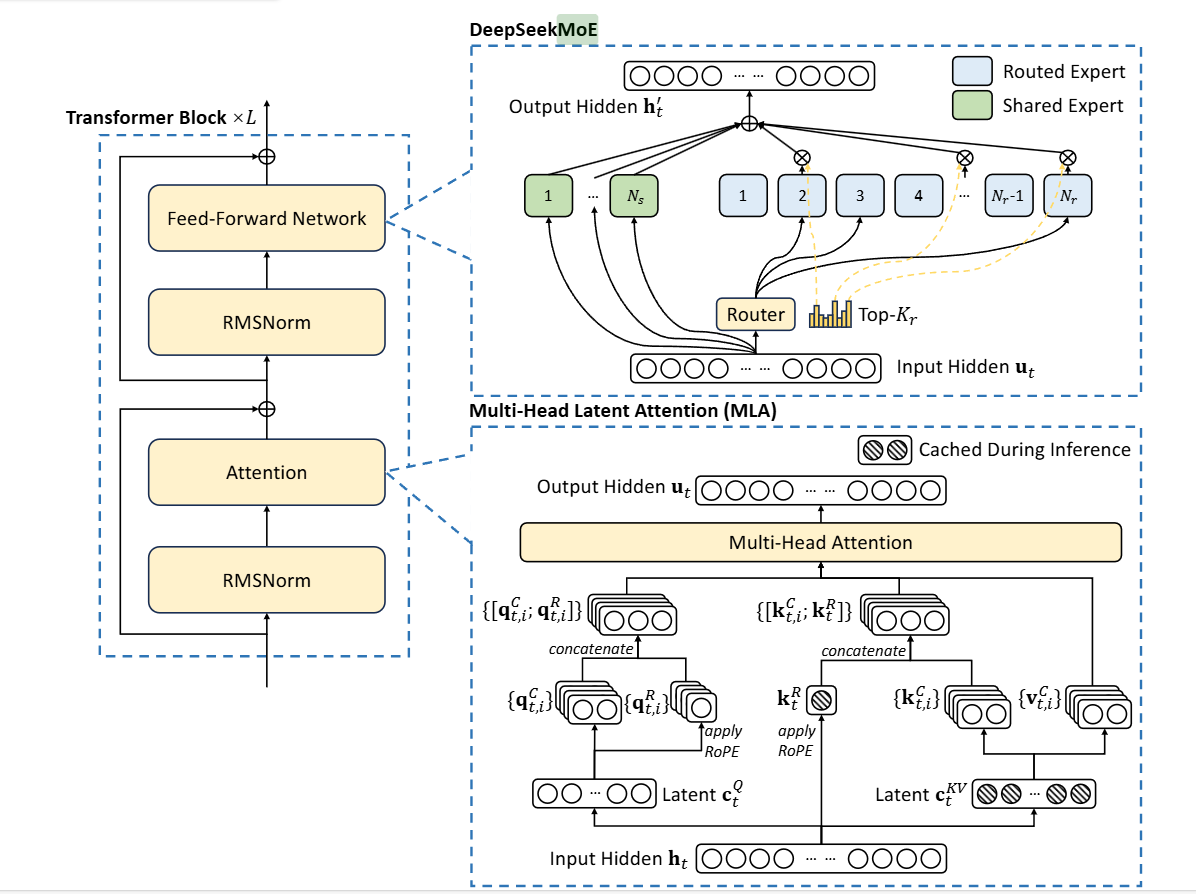
3.2 DeepSeekMoE
其中,shared Expert为Worker之间共享的,参数也会同步共享,而Routed Expert则是路由专家,每个Worker独有的,在门控网络部分,即如图的Router部分,Deepseek-V3中引入了无辅助损耗负载均衡,同时使用sigmoid函数作为亲和力得分的计算。具体公式如下:
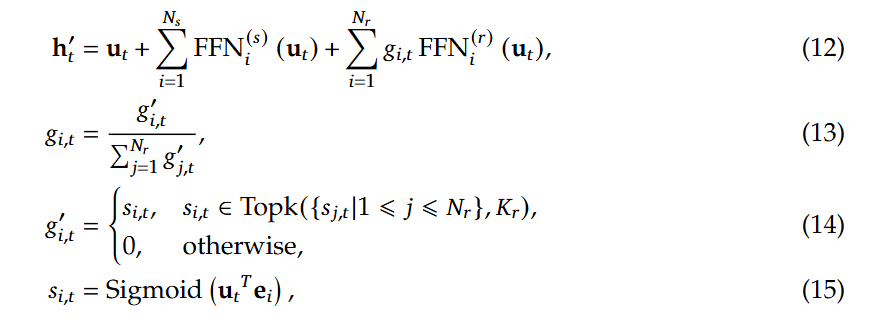
这里的 h'~t~的每一项分别为 input hidden 、共享专家输出之和,以及路由专家的加权求和,这里的权重g~i,t~是通过对每个g'~i,t~归一化得到的,除了tok个最大的亲和力得分的g'~i,t~为S~i,t~,其它均为0,这里的g~i,t~即门限值,即与FFN输出相乘的权重。
而无辅助损耗负载均衡(Auxiliary-Loss-Free Load Balancing),对应公式如下,在训练步骤的每个批次,会对专家负荷进行监控,每一步结束时,对应的专家超载,则将偏差项减小γ,若负载不足,则增大,其中 γ 是一个称为偏差更新速度的超参数,偏置b只用于负载均衡。
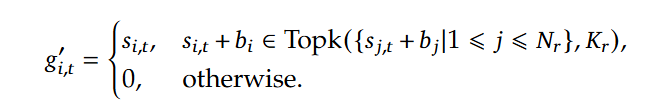
为了防止任何单个序列内的极端不平衡,还采用了一种互补的顺序平衡损耗,
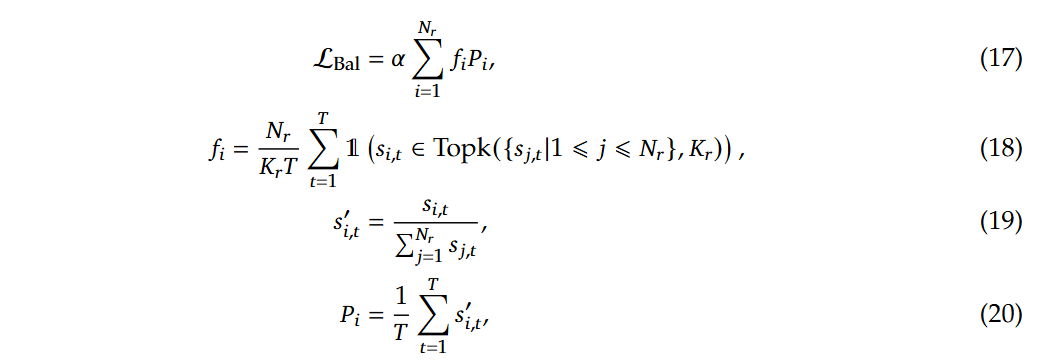
如公式(19)所示,为第i个专家对于第t个token的亲和力得分在所有专家对于该token的亲和力得分下的标准化,而公式(20)得到的P~i~即为第i个专家对于所有的token的亲和力得分标准化后的均值,对于f~i~,T表示序列中标记的数量,因此该公式表示(整个序列的所有token对于第i个专家的平均最大亲和力得分,以top_k和T值做平均)*N~r~,N~r~即路由专家的个数。α是一个超参数,会设置为一个很小的值。
3.3 MTP Modules
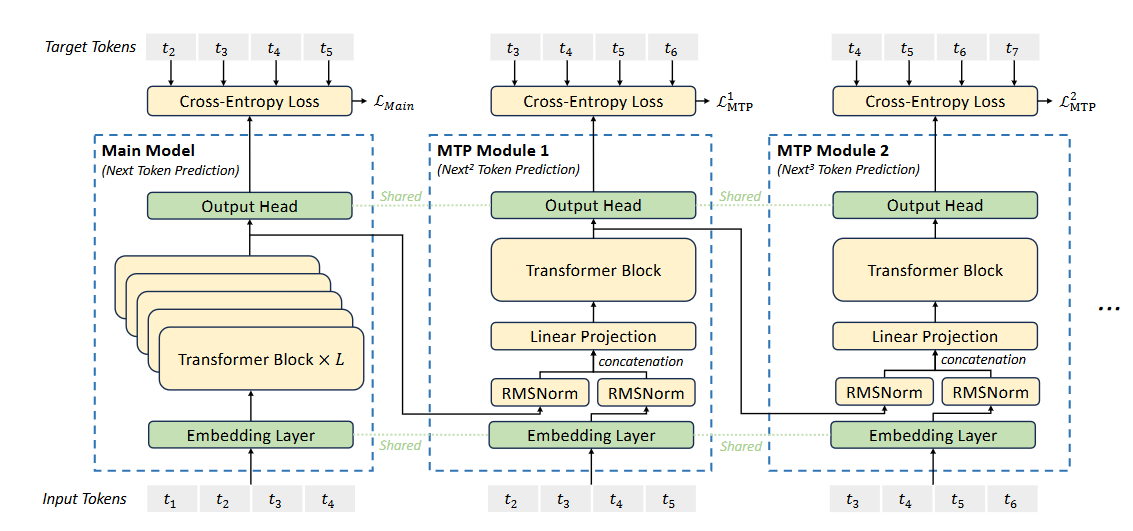
4.DualPipe
只需要保证pp_degree(pp_stage_nums)和acc_step(micro_batch_nums)被2整除,不需要acc_step被pp_degree整除。同时bubble和activation memory都不会随着acc_step的数量增加而增加。
4.1 forward阶段
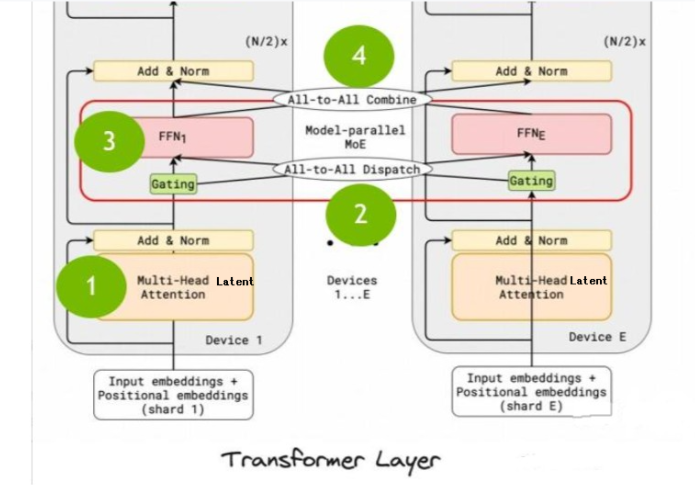
前向过程中,包括了四个主要的步骤:
- multi-head Latent attention层的计算;
- all-to-all dispatch,信息分发到各个node;为的是计算moe做准备(总是需要把token分发到M个机器上)
- model parallel MOE,模型并行MOE,也就是deepseekMOE;各专家独立执行FFN的计算(MLP层),即多个Experts,;
- all-to-all combine,M个机器的MOE计算完成之后,将各专家的输出加权求和,返回最终结果。
即 ATTN(F)->DISPATCH(F)->MLP(F)->COMBINE(F)
4.2 backward阶段
与前向过程反过来求梯度
COMBINE(B)->MLP(B)->DISPATCH(B)->ATTN(B)

![]()
![]()
而deepseek_V3又将其backward阶段分为了B和W,即B对应输入的activation x求导(在模型中可以看做隐藏层结果计算这一步,对隐藏层yi求导),W即对权重w求导,backward过程中,第i-1层的梯度计算,只需要得到第i层输入xi(等价第i-1层输出,yi-1)的梯度,因此第i-1层的B阶段依赖于第i层的B阶段,而W~i~只依赖于B~i~,在B~i~计算完成后即可。
4.3 编排方式

相比于ZB-PP,除了F,B,W的拆分外,DualPipe还在通信/计算的维度上拆分任务,将F和B过程进一步拆分为:
- 计算:MLP(F),MLP(B),ATTN(F),ATTN(B)
- 通信:DISPATCH(F)DISPATCH(B),COMBINE(F),COMBINE(B)
(猜测:图中紫色的PP部分是在同一层模型的不同拷贝之间进行同步权重或者梯度的通信过程)
通过调节GPU的流处理器的分配比例,可以保证通信部分的时间和计算的时间匹配上(即途中的上下两行对齐的效果),从而省去因通信而产生的GPU计算空闲。
在模型层分配的设计上,DualPipe中采用了如下的设计:
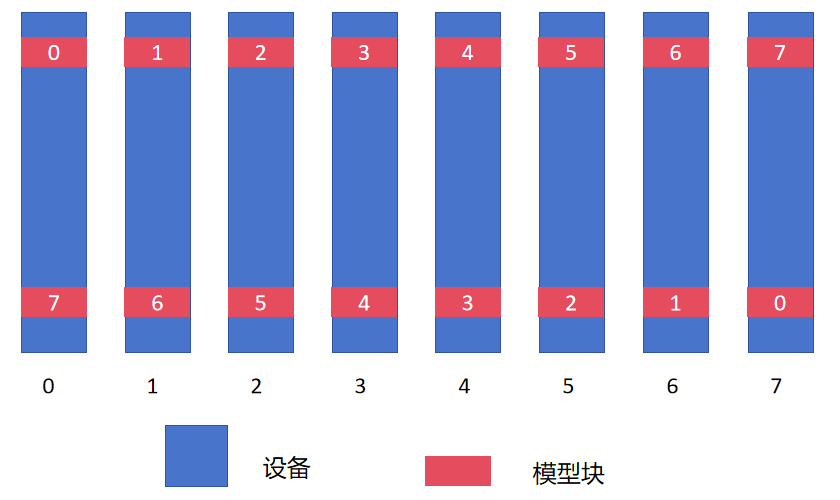
这样的设计使得在前向和后向计算时卡间的顺序都可以保持一致,不同卡上的同一组参数其更新时间也可以保持一致(由图中的上下对称性可知)。同时从两端输入批次进行训练。
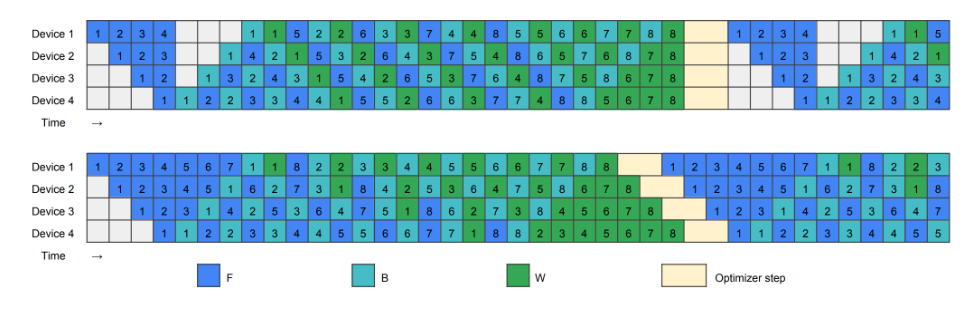
以下是dualpipe的编排情况,如下图所示:

其中:
![]()
对应
这样做可以在执行过程中,完全隐藏: all to all和 PP 通信
选用all to all 的原因
- 动态路由的不可预测性,无法提前确定通信目标。
- 批次内专家覆盖的全局性,导致设备间需交换全量数据。
- 硬件优化的集体通信效率,远高于动态点对点通信。
- 反向传播的对称性需求,确保梯度正确传递。
4.4 编排核心解析

红色箭头和蓝色箭头分别代表一个micro_batch,因为每个设备上保留了两个模型块,所以分别是从设备0 和设备 7 对称开始,在某个阶段,在同一个设备上,出现一个模型块做forward,另一个模型块做backward,并且编排后可重叠计算与通信。