动态流水并行开发知识记录
PipelineStage开发记录
1.根据维度名称获取mesh
代码如下:
def get_mesh_with_dim(
self,
dim_name: str,
index: slice | tuple[slice, ...] | SupportsIndex | None = None,
) -> ProcessMesh:
assert (
dim_name in self._dim_names
), f'{dim_name} is not a valid dim name.'
index_axis = self._dim_names.index(dim_name)
new_order = [index_axis] + [
i for i in range(len(self._dim_names)) if i != index_axis
]
new_dim_names = [dim_name] + [
dim for dim in self._dim_names if dim != dim_name
]
new_mesh = self._mesh.transpose(new_order)
if index is not None:
return ProcessMesh(new_mesh[index], new_dim_names[1:])
return ProcessMesh(new_mesh, new_dim_names)
原来的mesh:
[
[ [1, 2], [3, 4] ],
[ [5, 6], [7, 8] ]
]
大小为:2 2 2 ,dim_names=["dp","mp","pp"]
此时使用get_mesh_with_dim("pp")
则,得到的mesh为:
[
[[1, 3], [5, 7]], # pp=0
[[2, 4], [6, 8]], # pp=1
]
即,将pp这个维度提前到最前面,此时:大小为:2 2 2 ,dim_names=["pp","dp","mp"]
dim_name和index联合使用的时候,首先将dim_name提到最前面,调整mesh的数据分布,紧接着,取index指定的那一条,这时候,比如dim_name是pp,而取某个index,就像是取某个pp_stage,此时内部就没有pp概念了,所以把pp这一维度去掉,所以有new_dim_names[1:]。
2.递归显式调用
def extract_tensors_with_grads(
output_val,
grad_val,
extract_tensors_with_grads,
):
if isinstance(output_val, paddle.Tensor):
if output_val.stop_gradient and output_val.grad_fn is None:
return
assert isinstance(
grad_val, (paddle.Tensor, type(None))
), f"Expected Tensor or None gradient but got {type(grad_val)}"
stage_output_tensors.append(output_val)
output_grad_tensors.append(grad_val)
elif isinstance(output_val, (tuple, list)):
if grad_val is None:
return
assert isinstance(
grad_val, (tuple, list)
), f"grad_value expected to have type {type(output_val)} but got {type(grad_val)}"
assert len(output_val) == len(grad_val)
for ov, gv in zip(output_val, grad_val):
extract_tensors_with_grads(
ov,
gv,
extract_tensors_with_grads,
)
extract_tensors_with_grads作为参数显示调用,原因是,函数参数的生命周期会在函数执行完后结束,那么再递归调用的过程中,最里层的一次函数调用处理完return后,这一层的函数调用所占用的内存空间(函数引用的这部分)会立即释放。而如果直接递归调用自己,则会形成引用换环,直到递归完全结束后,等到垃圾回收机制(gc)处理。
3.装饰器的使用
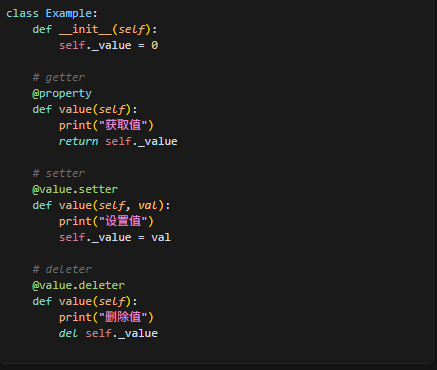
装饰器的三种使用,使用装饰器,可以直接像访问普通属性一样,如下:
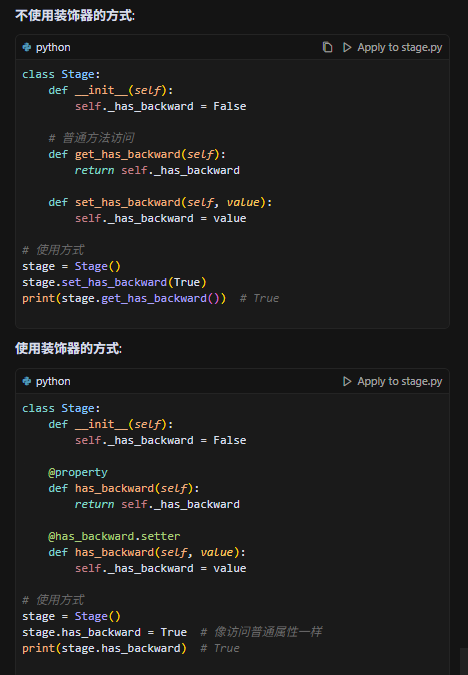
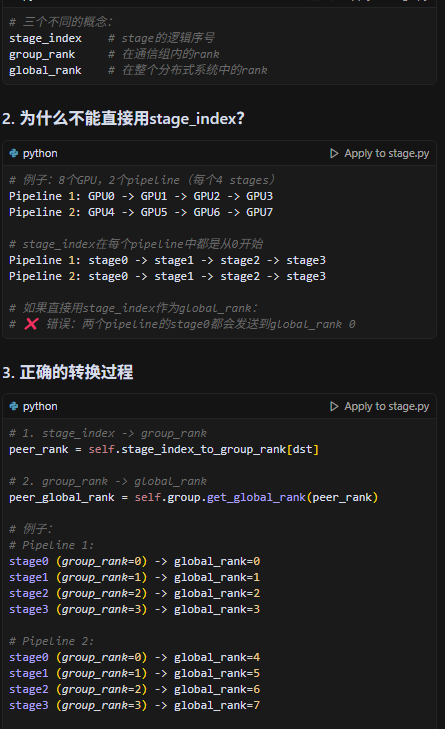
4.stage_index,group_rank,global_rank三种概念
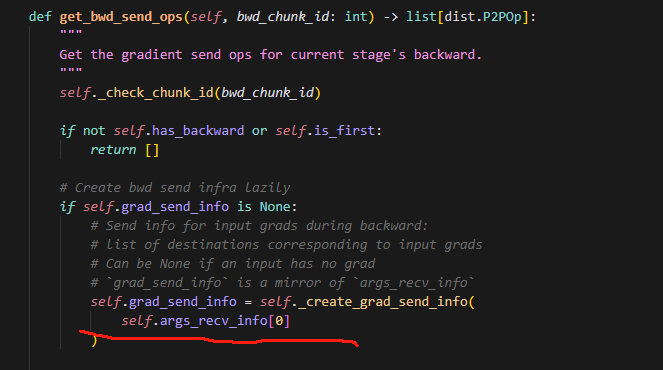
5.为什么只用self.args_recv_info[0]?
因为所有微批次的接收信息都一样,如果stage1从stage0接收数据,那么所有微批次都是这样的,因此选一个微批次,从中获取接收的源stage是谁就行。
6.clear_runtime_stages的使用和时机
我们在每次backward前调用它,主要是为了确保,每次反向前,前一次的信息都被清理了,而且不单单清理梯度,同时还要清理前向缓存和输出缓存。
(存疑,因为代码中的表现,clear_runtime_stages只在_prepare_backward_infra中被使用,而此时清楚的states,应该是_shape_inference过程创建的states,但存疑,不太确定,因为只用了一个地方)forward缓存是为了backward时计算梯度需要使用到的forward过程中涉及到的参数,并且保存了输出值,而output_chunk缓存,则是用来存储每个micro_batch的输出(相当于forward缓存的一个子集,只不过forward为了保持格式转化成了tuple,而output_chunk保存了输出的原格式),最后对所有micro_batch的输出做规约,例如平均,等操作。
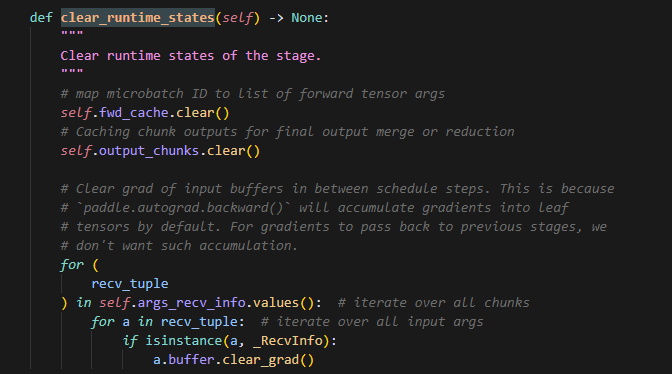
7.paddle.autograd.backward示例
注意这里传入的参数,tensors,grad_tensors,retain_graph,为什么计算grad要前两个参数,因为首先无论计算w(权重梯度)还是b(输入梯度)的grad,都需要当前层输出的梯度,用于梯度累乘,而tensors则是用来告知函数,当前需要从计算图的哪个点开始计算梯度。
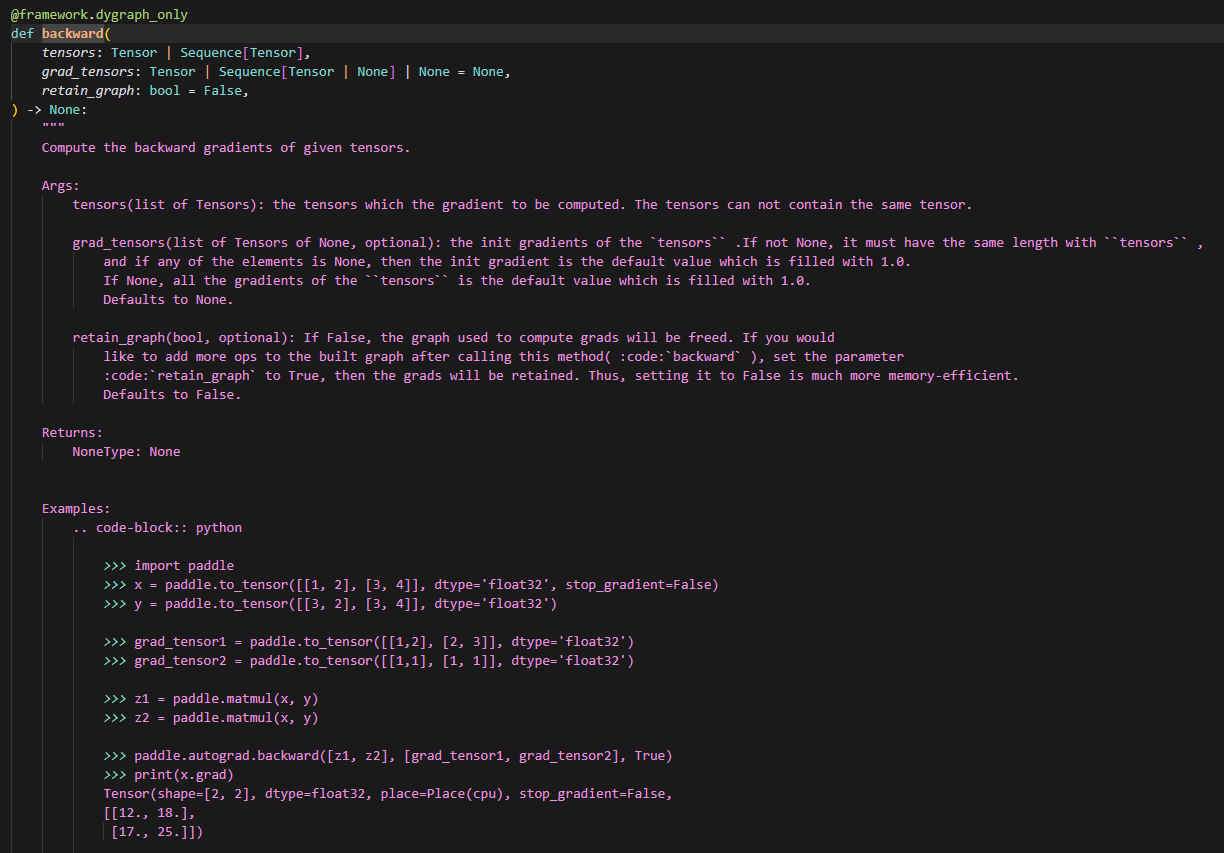
计算过程:
8.匿名函数的执行时机
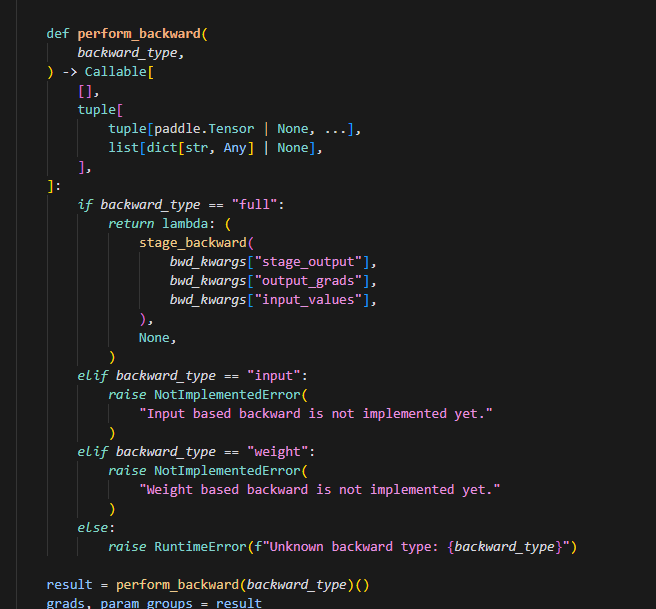
这里lambda:(stage_backward(),None,)是一个匿名函数,func=preform_backward(backward_type)时不执行,再使用func()才执行。
9.接收对象列表大小为1,为什么?
目前经过代码分析,我认为应该是所有的传递的数据都被包装成了(output,)这种tuple的形式,所以只需要大小为1,取第一个元素即可。
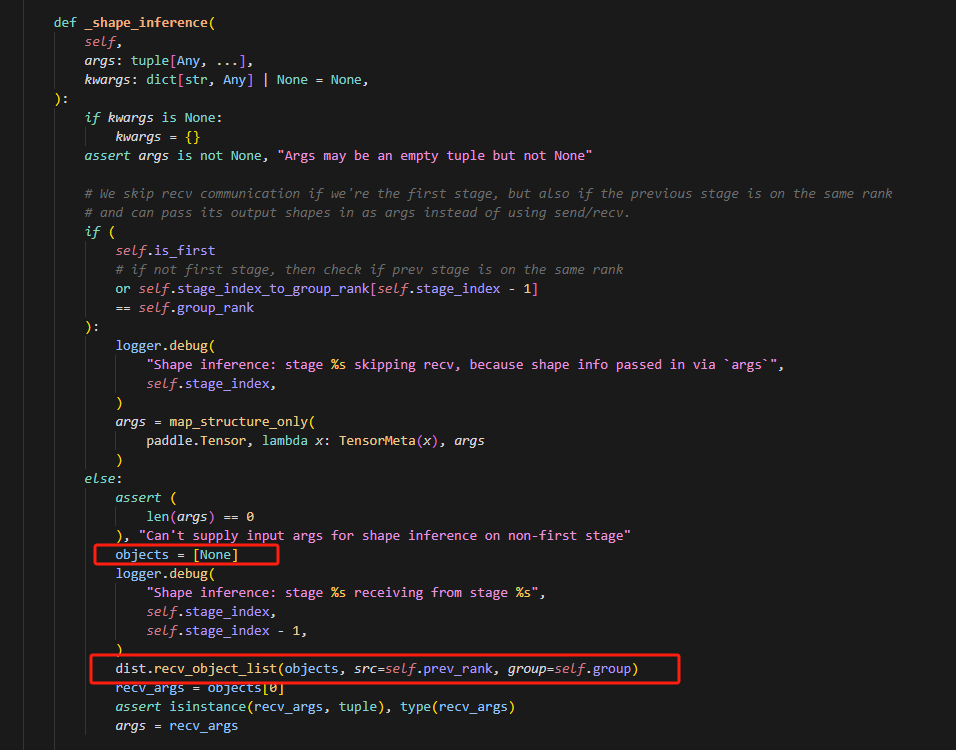
10.形状推理函数中的分析
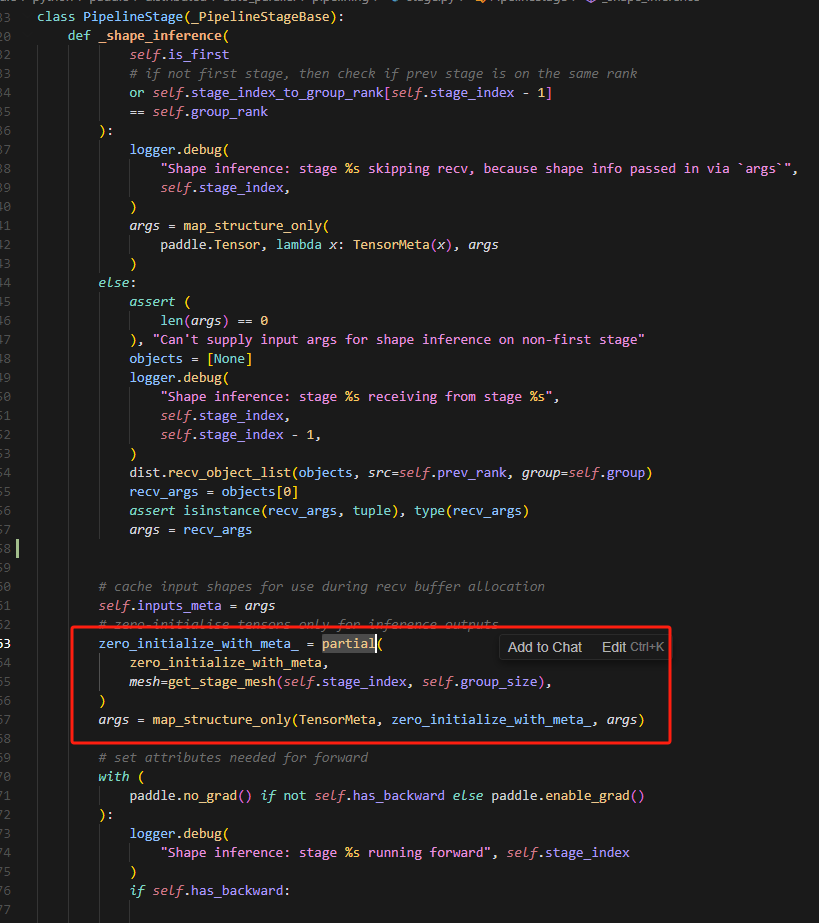
这里首先使用partial是为了固定函数zero_initialize_with_meta的参数mesh,使代码简洁化,同时对每一个参数都是用zero_initialize_with_meta函数处理,其实主要是根据args大小创建数值均为0的张量,模拟计算,推理大小。
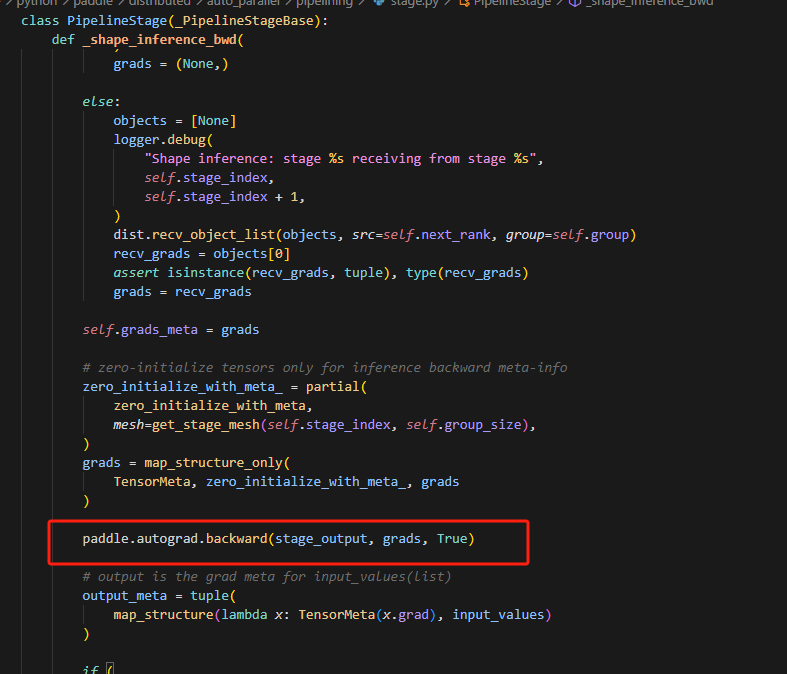
11.为什么实际backward时候不保留计算图,而形状推理中的backward要保留计算图
因为对于每一个microbatch来说,在backward的时候,每一步数据的大小是一样的,所以复用一个即可;而真实进行backward的时候,每个microbatch对应不同的计算图,因此不用保留,处理完立即释放即可。
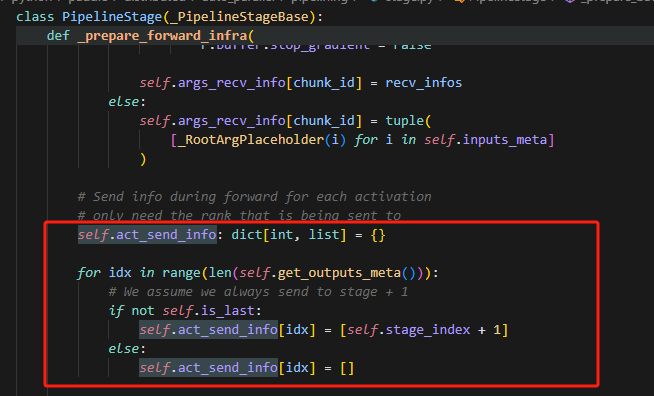
12.记录act_send_info作用
实际就是记录了每个输出要发送到的目标stage的index,即当前stage+1
13.全序通信,一致性排序原则
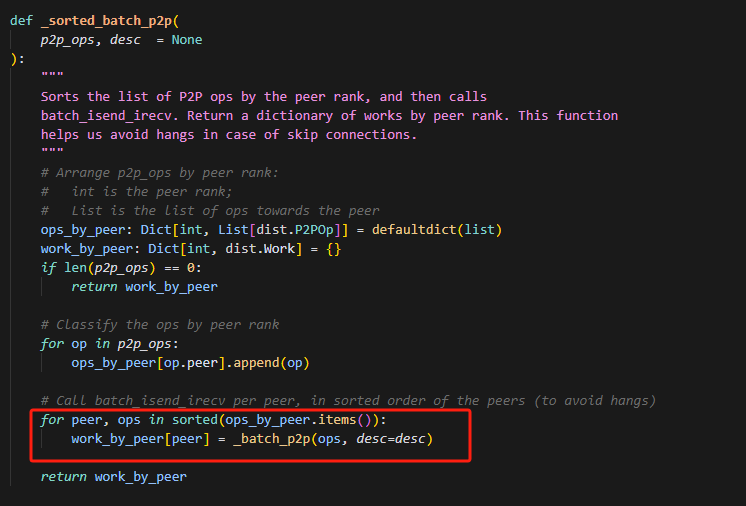
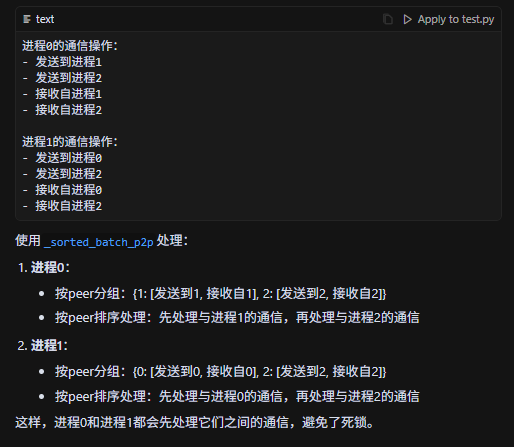
所有进程都按照升序来处理op,可以避免死锁。,具体示例如下:
14.为什么在同一个rank上的stage需要做detach?
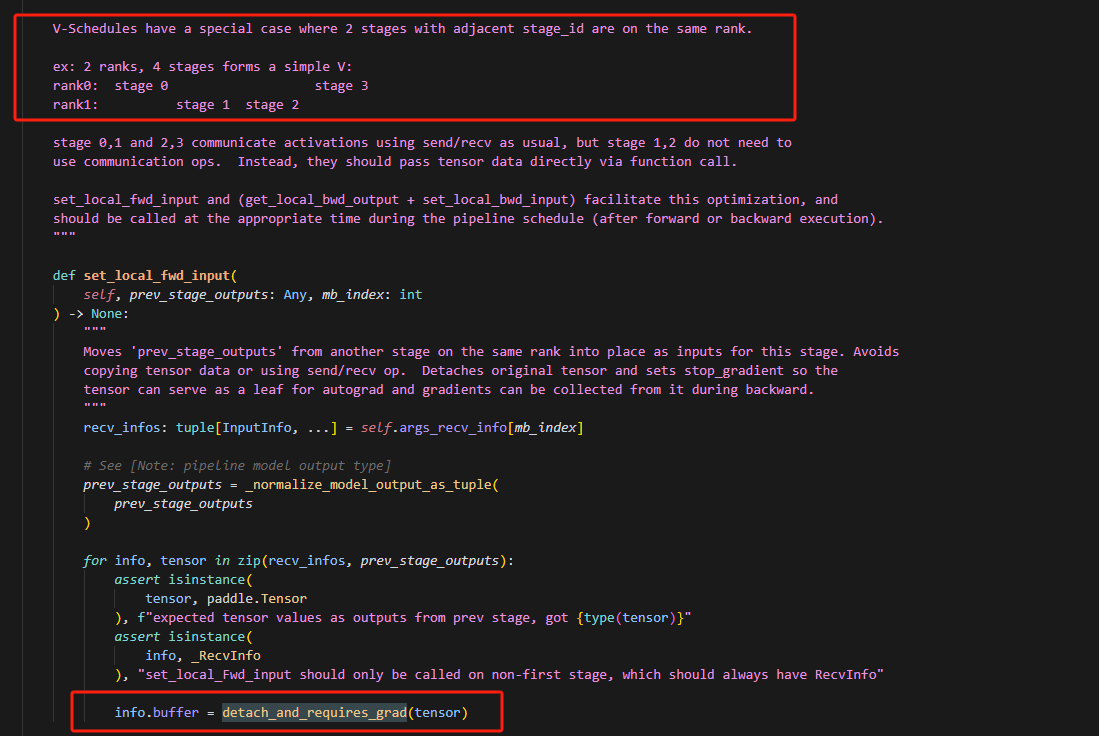
因为对于不同的stage来说,传递的数据本身就是通过P2P算子传递的,因此计算图本身就是分开的,而如果在同一个rank下,直接赋值,此时计算图就会通过上一个stage的输出=下一个stage的输出连接起来,因此为了和不同rank上的stage保持一致,这里需要detach,同时因为除了第一个stage,每个stage的输入都是要计算梯度的,因此需要设置梯度。
这里判断是否有RecvInfo,是因为第一个stage的输入是没有RecvInfo的,是直接通过传递参数得到的,因此无需设置input。
15.PipelineStage的数据传输过程
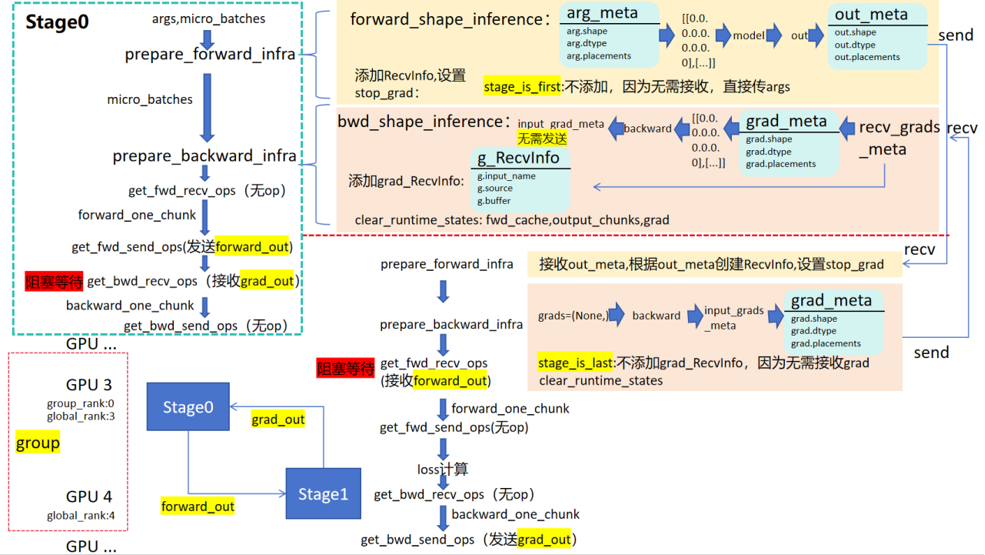
16.为什么backward只有三个参数,当前stage的输出,输出的梯度,是否保留计算图;而没有forward的参数,但可以做反向的梯度计算?
- 首先,在前向传播时,每个算子的结果会被保存在 GradNode 中:
// 在前向计算时,会创建GradNode并保存在tensor的AutogradMeta中
AutogradMeta* auto_grad_meta = EagerUtils::nullable_autograd_meta(tensor);
auto shared_grad_node = auto_grad_meta->GetMutableGradNode();
- 在 RunBackward 中获取这些节点:
for (size_t i = 0; i < tensors.size(); i++) {
const paddle::Tensor& tensor = tensors[i];
// 从tensor中获取AutogradMeta
AutogradMeta* auto_grad_meta = EagerUtils::nullable_autograd_meta(tensor);
if (auto_grad_meta == nullptr) {
VLOG(5) << "Skip auto grad since there is no grad op for var or loss is "
"stop_gradient=True: "
<< tensor.name();
continue;
}
// 从AutogradMeta中获取GradNode
auto input_info = auto_grad_meta->OutRankInfo();
VLOG(5) << "Out Rank of Tensor is slot: " << input_info.first
<< ", rank: " << input_info.second;
auto shared_grad_node = auto_grad_meta->GetMutableGradNode();
GradNodeBase* grad_node = shared_grad_node.get();
}
- 关键在于 GradNode 中保存了前向计算的中间结果:
// 检查GradNode是否还保留着TensorWrappers(前向结果)
void EnforceGradNodeHasInput(GradNodeBase* node) {
PADDLE_ENFORCE_NE(
node->IsTensorWrappersCleared(),
true,
common::errors::Fatal(
"The TensorWrappers of %s do not exist. This may be because:\n"
"You calculate backward twice for the same subgraph without "
"setting retain_graph=True. Please set retain_graph=True in the "
"first backward/grad call.\n",
node->name()));
}
- 在反向计算时使用这些结果:
// 运行反向节点,使用保存的前向结果
paddle::small_vector<std::vector<paddle::Tensor>, kSlotSmallVectorSize>
grad_output_tensors = (*node)(
node_input_buffer->Buffers(), create_graph, is_general_grad);
// 如果不保留计算图,清除前向结果
if (!retain_graph) {
VLOG(3) << "retain_graph is false, need to clear the TensorWrapper of nodes.";
node->ClearTensorWrappers();
}
整个流程是:
前向计算时:
- 每个算子创建对应的 GradNode
- GradNode 保存必要的中间结果(TensorWrappers)
- GradNode 被保存在输出 tensor 的 AutogradMeta 中
反向计算时:
- 从最终输出 tensor 开始
- 通过 AutogradMeta 获取 GradNode
- GradNode 使用保存的前向结果计算梯度
- 如果 retain_graph=false,计算完就清除前向结果
这就是为什么:
- 默认情况下不能对同一个图做两次反向(因为第一次后清除了前向结果)
- 如果需要多次反向,必须设置 retain_graph=True
- 保存前向结果会占用额外内存
这种设计允许:
- 内存优化:不需要时立即释放前向结果
- 灵活控制:用户可以决定是否保留计算图
- 准确性:确保反向计算时能访问到所需的所有前向信息
16.原来开发的代码,如果模型有偏置会报错
错误问题:最后一个stage的偏置的梯度计算,和分布式框架做的并行训练以及单卡训练得到的偏置梯度都不一样。
追溯后的原因:原因是在做inference的时候,最开始做backward的时候,给的grad是None,在backward内部实现的时候,会默认最开始的first_grad为1进行求导(即在最后一个stage上进行),此时最后一个stage做梯度计算时,以最后一层为例,bias的梯度会缓存,而weight的梯度由于等于first_grad*input_tensor,此时做inference时,input_tensor是zero_tensor,所以weight梯度计算为zero_tensor即使缓存也不影响,而bias的梯度则会在正式开始backward的时候累加,导致bias梯度出现错误。
为什么前面的stage不出问题:可以看到下图,对于不为None的grads,即其它stage,非laststage,它们的grads都是从其它stage接收的,而这些非None的grad会被zero_initialize_with_meta函数处理,即非last_stage的所有stage的初始传入进行梯度计算的grad均为zero_tensor,因此其它的stage,无论是bias还是weight都是zero_tensor不会被影响。
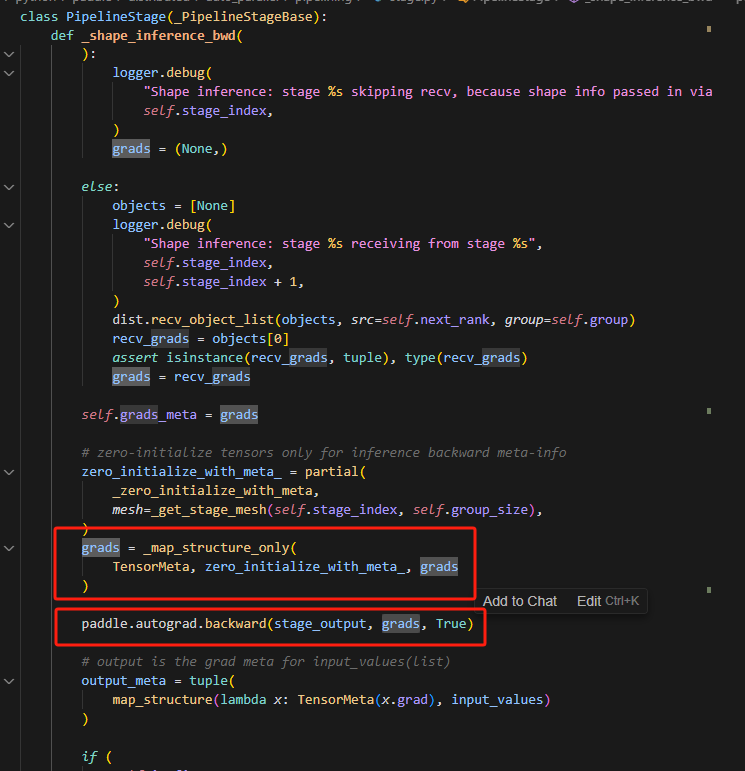
修改方法一共两种:
1.shape_inference_bwd从最后一个结点做反向的时候,给的grads是None,那么backward会默认从梯度为1开始求导,所以shape_inference_bwd之后,bias的偏置就改变了,后面再做正式的backward的时候,两个bias就叠加了,因此可以把这里的grads根据stage_output的形状,使用paddle.zeros_like创建0tensor作为初始梯度。修改代码如下:
将_shape_inference_bwd中的is_last的情况的grads=(None,)替换如下:
grads = _map_structure_only(
paddle.Tensor, paddle.zeros_like, stage_output
)
last_output_grads_meta = tuple(
map_structure(lambda x: TensorMeta(x), grads)
)
grads = last_output_grads_meta
2.因为做完shape_inference_bwd后,会有clear_runtime_states;可以在clear_runtime_states里面加一个模型参数的梯度清空操作,如图  ,只是我们只需要清空的是最后一个stage的bias的梯度,因此可能会存在开销浪费。
,只是我们只需要清空的是最后一个stage的bias的梯度,因此可能会存在开销浪费。
Schedules开发记录
1.为什么这里剩下的forward不逻辑发送,而是和backward融合发送
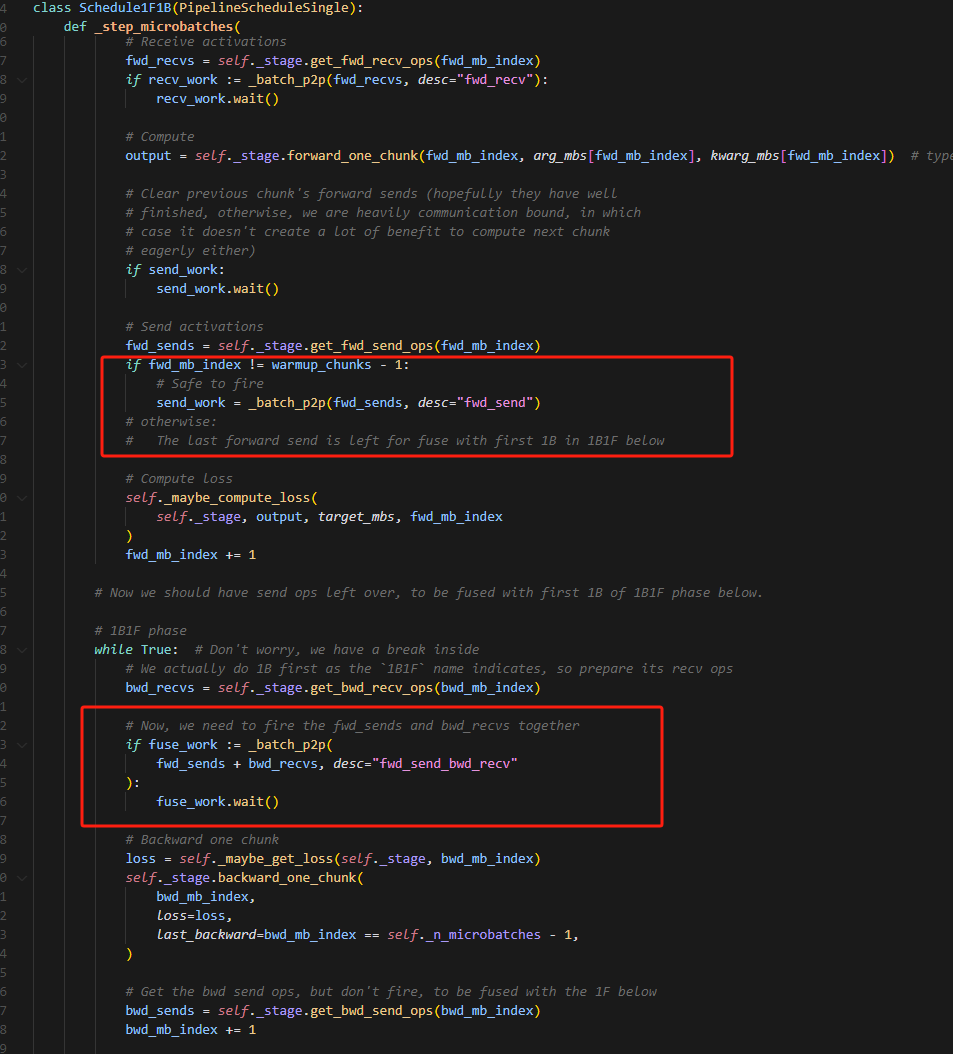
主要是batch_isend_irecv在执行op的时候,需要获取通信资源,初始化上下文等操作,如果1F1B(注意这里是1B1F,但不影响)不融合,则要两次获取通信资源,初始化上下文,造成通信开销,因此这里选择融合每一个1F1B
2.这段代码,看起来是先forward_one_chunk,再recv_forward,不会出错吗?
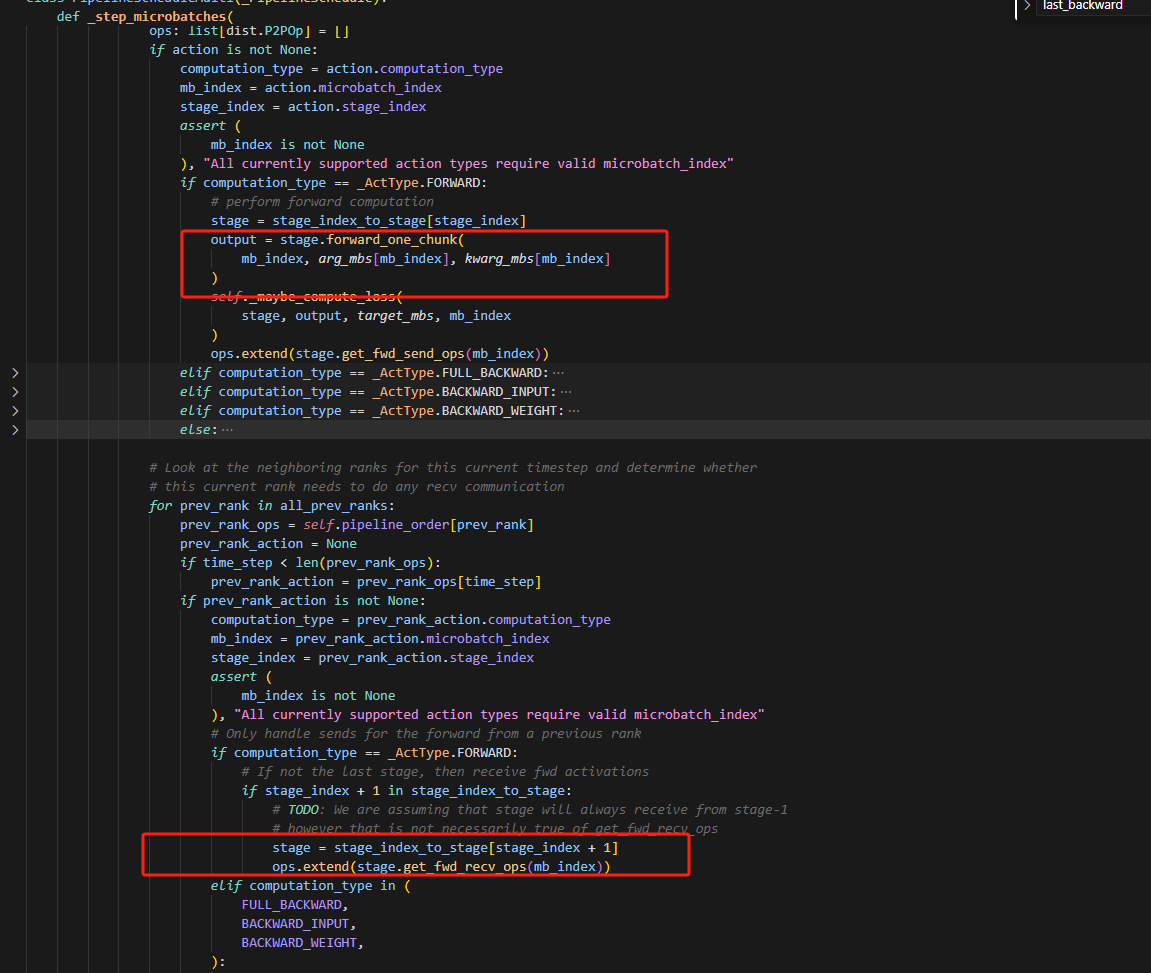
从代码上看确实是这个顺序,关键在于self.pipeline_order,例如在time_step=0的时间步,stage0在rank0上做forward,是first_stage不用接收数据,而此时rank1的self.pipeline_order,time_step=0的时间步对应的action将被设置为None,因此不会做forward,而是会到下面代码去判断是否需要接收数据。
3.backward_counter是做什么的,为什么这么赋值last_backward
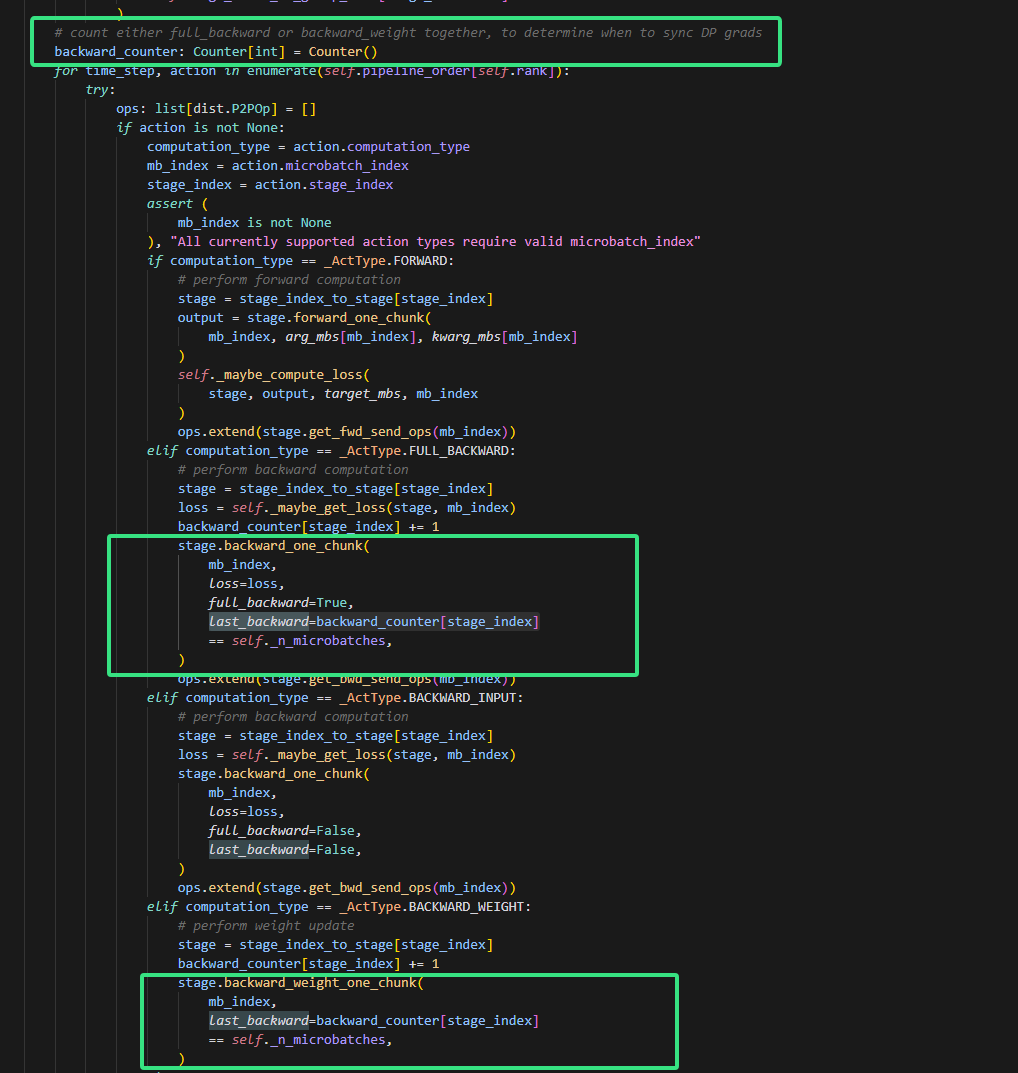
- 首先看
backward_counter的定义和使用:
# 初始化计数器
backward_counter: Counter[int] = Counter()
# 在backward时增加计数
backward_counter[stage_index] += 1
# 判断是否是最后一个backward
last_backward = backward_counter[stage_index] == self._n_microbatches
- 再看
backward_one_chunk函数的注释:
"""
last_backward is controlled by the schedule and signals synchronization of gradients across DP groups
after the last backward.
"""
这个设计的含义是:
- 在pipeline并行中,一个大batch被分成了多个microbatch
- 每个stage都要对每个microbatch做backward
backward_counter记录每个stage已经处理了多少个microbatch的backward- 当某个stage处理完所有microbatch的backward时(即
backward_counter[stage_index] == n_microbatches) - 这时就是这个stage的"最后一个backward",需要同步数据并行(DP)组之间的梯度
举个例子:
# 假设有3个microbatch
n_microbatches = 3
# Stage 0处理第一个microbatch的backward
backward_counter[0] = 1
last_backward = (1 == 3) # False
# Stage 0处理第二个microbatch的backward
backward_counter[0] = 2
last_backward = (2 == 3) # False
# Stage 0处理第三个microbatch的backward
backward_counter[0] = 3
last_backward = (3 == 3) # True,这是最后一个backward,需要同步梯度
这种设计的目的是:
- 只在处理完所有microbatch后才同步梯度
- 避免频繁的梯度同步带来的性能开销
- 确保梯度累积的正确性
4.self.microbatches_per_round的含义
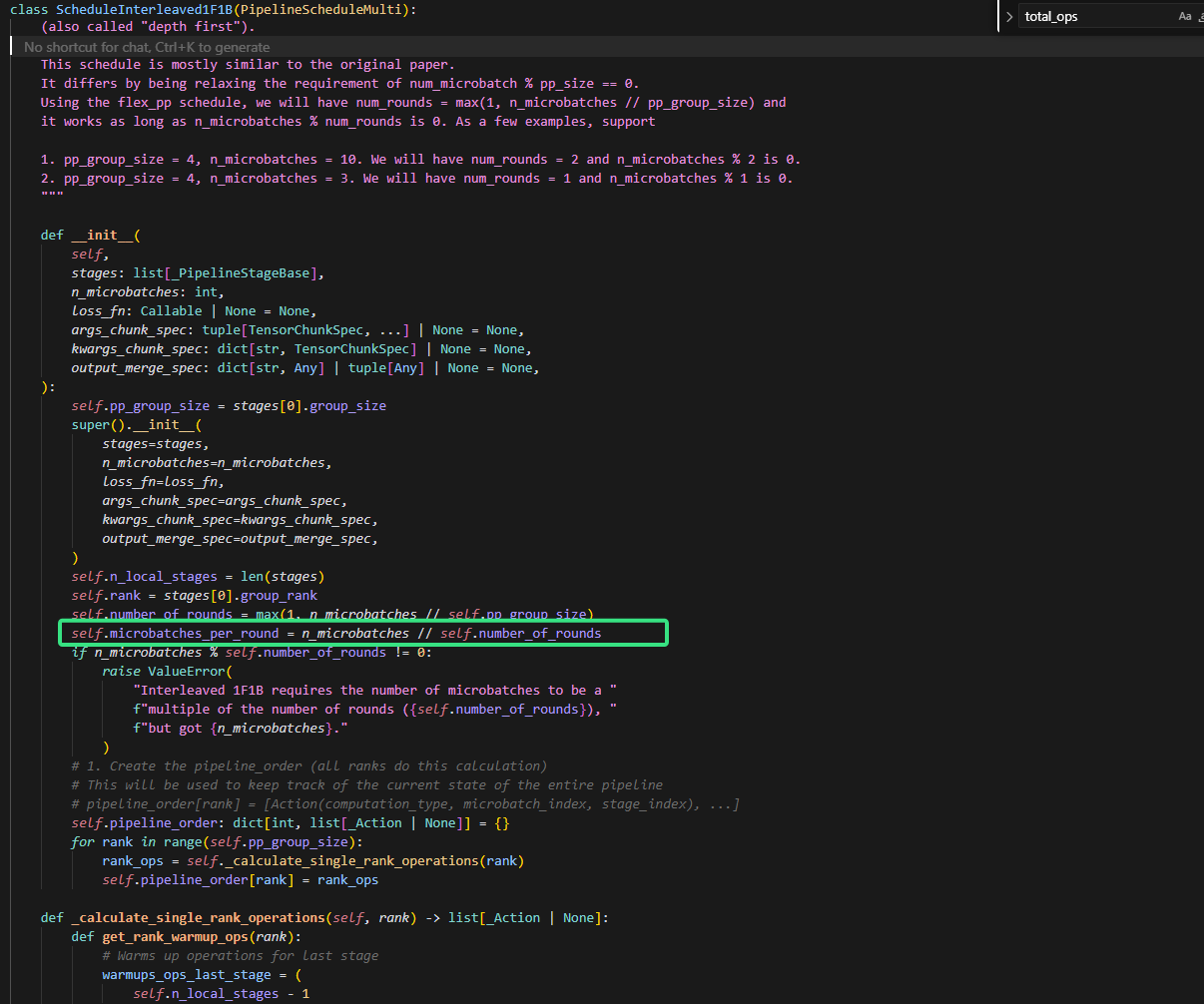
self.number_of_rounds是为了放宽num_microbatch % pp_size == 0这个条件而设定的,而self*.microbatches_per_round的含义是:对于rank_i,每给当前stage排多少个action(一个microbatche对应一个action)就,换下一个stage排action。
5.怎么理解forward_stage_index
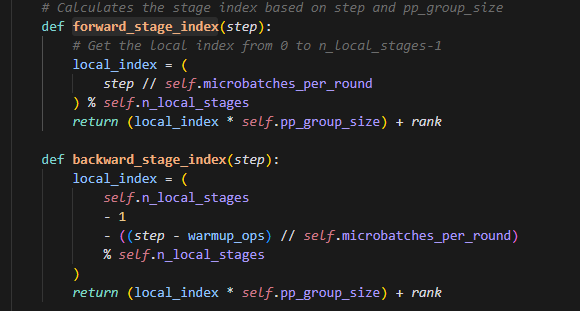
step就是遍历总step时候的一个对象,此时我们想知道当前step在哪个stage上,我们从4可以知道,每self.microbatches_per_round换一次stage,因此先整除,再求余。即每换一轮stage的数是self.n_local_stages,而余数就可以表示当前所处的这轮,轮到哪个stage了。
6.理解参数self.stage_index_to_group_rank
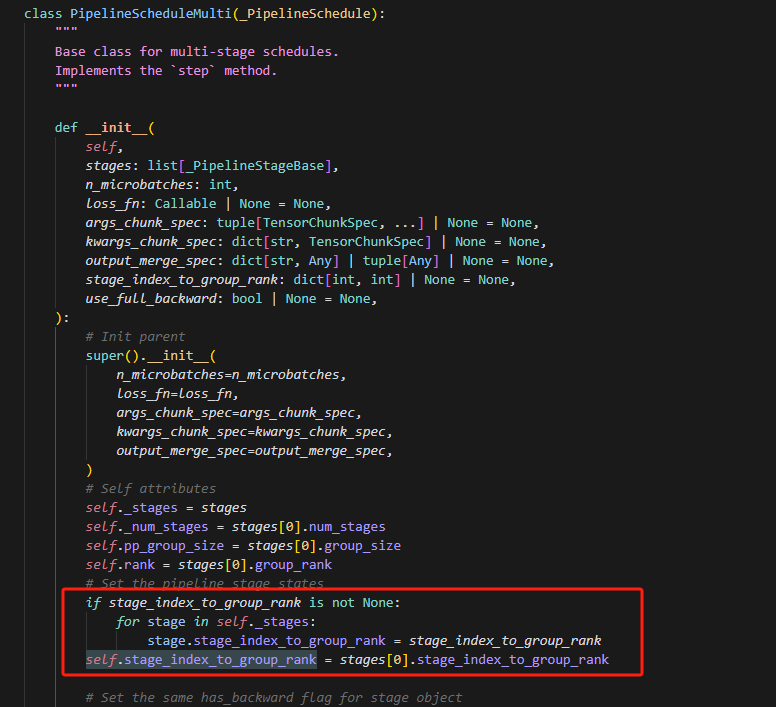

如上,比如当有8个stage的时候,有4个GPU,即group_size=4,则stage_index_to_group_rank为:
{“0”:0,“1”:1,“2”:2,“3”:3,“4”:0,“5”:1,“6”:2,“7”:3}