自动并行训练知识点记录
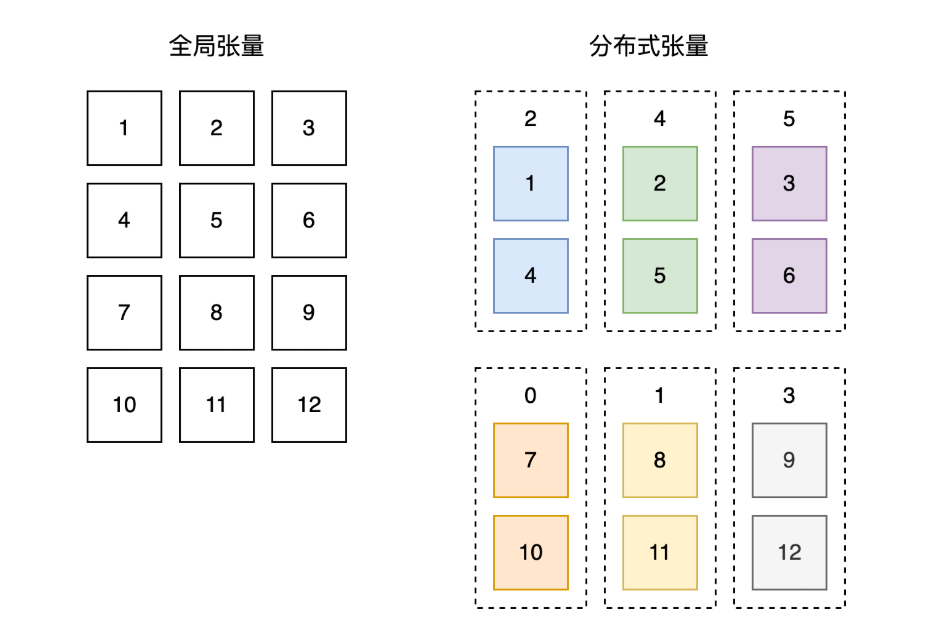
1.tensor在不同视角下的名称
单卡视角下:dense_tensor(只在单独的设备上计算,没有设备间通信)
多卡视角下:dist_tensor (会有一些分布式属性,有设备间通信)
import paddle
import paddle.distributed as dist
mesh = dist.ProcessMesh([[2, 4, 5], [0, 1, 3]], dim_names=['x', 'y'])
dense_tensor = paddle.to_tensor([[1,2,3],
[4,5,6],
[7,8,9],
[10,11,12]])
placements = [dist.Shard(0), dist.Shard(1)]
dist_tensor = dist.shard_tensor(dense_tensor, mesh, placements)
2.张量分布式切分方式
- Replicate,指张量在所有计算设备上保持全量状态。
- Shard(axis),指将张量沿 axis 维度做切分后,放到不同的计算设备上。
- Partial,指每个计算设备只拥有部分值,需要通过指定的规约操作才能恢复成全量数据。
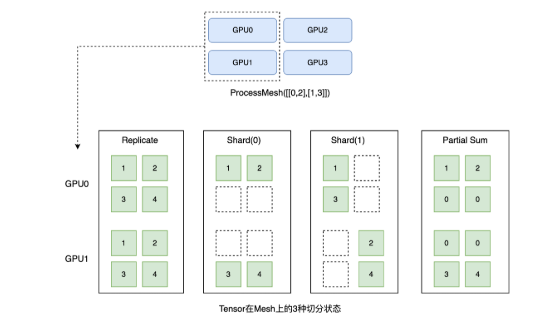
注意shard和partial的区别,shard是从物理上切分dense_tensor,将其按不同维度切分到不同的进程组中,再分配到对应设备上,而partial则是逻辑上切分,并不是做了实际的张量切分,只是一个概念,例如在数据并行中,每组数据在某个设备上会对于所有参数计算它们的一次梯度,而最终需要将每个mircro_batch计算的梯度做梯度累加,才是最终的梯度,因此此时单个设备上的梯度,就算是partial切分,而每个设备上保存的部分数据大小是一致的,和最后规约后的大小也是一致的。
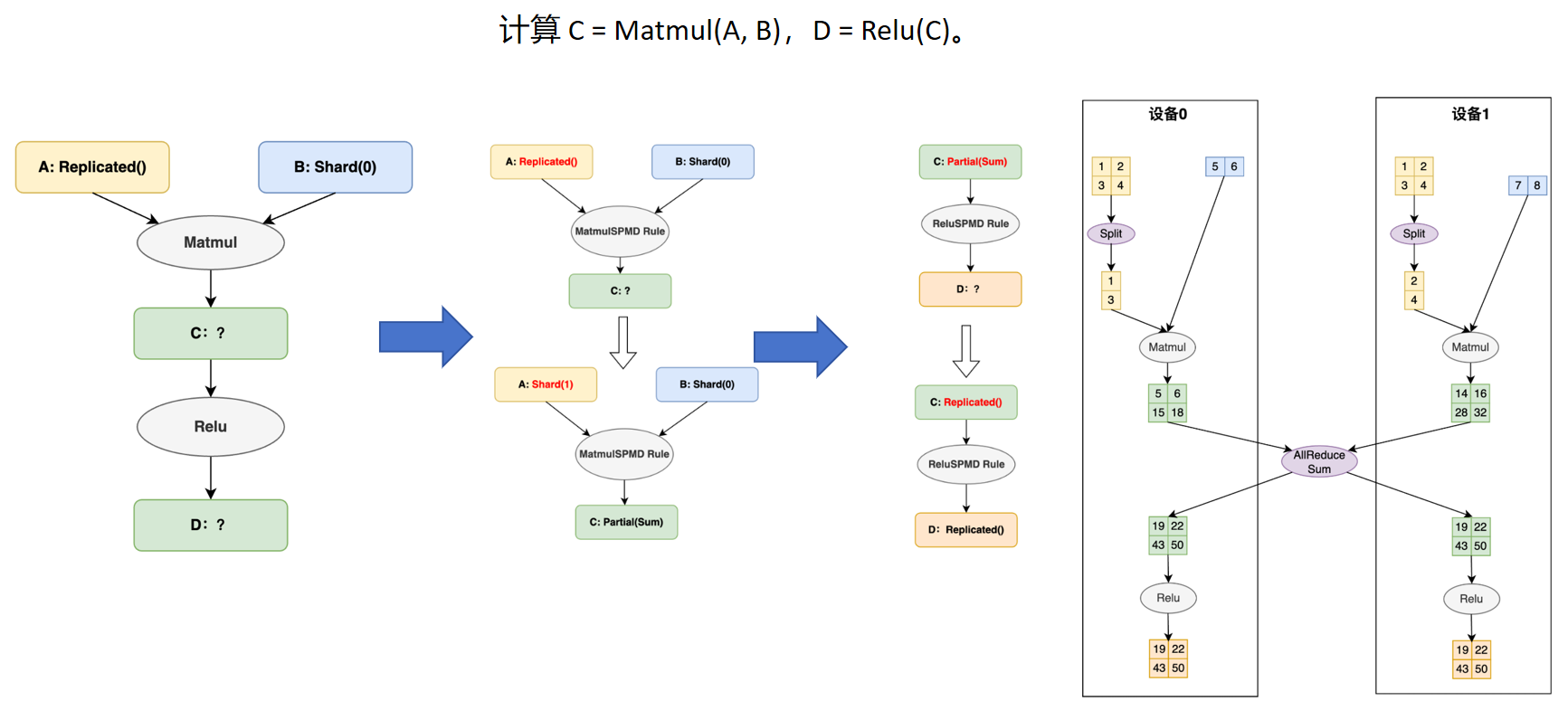
3.一个分布式的计算示例:
4.数据并行,模型并行,流水并行
4.1 数据并行
数据并行是将训练时一轮的数据,按照标记的切分方式,切分到各个设备上,每组数据在每个设备上进行一次forward,backward,最终在梯度计算完成后,进行梯度累加。
# 启动脚本:
# python3 -m paddle.distributed.launch --device=0,1,2,3 train.py
import paddle
import paddle.distributed as dist
from paddle.io import BatchSampler, DataLoader, Dataset
import numpy as np
mesh = dist.ProcessMesh([0, 1, 2, 3], dim_names=['x'])
class RandomDataset(Dataset):
def __init__(self, seq_len, hidden, num_samples=100):
super().__init__()
self.seq_len = seq_len
self.hidden = hidden
self.num_samples = num_samples
def __getitem__(self, index):
input = np.random.uniform(size=[self.seq_len, self.hidden]).astype("float32")
return input
def __len__(self):
return self.num_samples
class MlpModel(paddle.nn.Layer):
def __init__(self):
super(MlpModel, self).__init__()
self.w0 = self.create_parameter(shape=[1024, 4096])
self.w1 = self.create_parameter(shape=[4096, 1024])
def forward(self, x):
# 标记数据为切分状态
dist.shard_tensor(x, mesh, [dist.Shard(0)])
y = paddle.matmul(x, self.w0)
z = paddle.matmul(y, self.w1)
return z
model = MlpModel()
dataset = RandomDataset(128, 1024)
sampler = BatchSampler(
dataset,
batch_size=4,
)
dataloader = DataLoader(
dataset,
batch_sampler=sampler,
)
opt = paddle.optimizer.AdamW(learning_rate=0.001, parameters=model.parameters())
opt = dist.shard_optimizer(opt)
for step, inputs in enumerate(dataloader):
data = inputs
logits = model(data)
loss = paddle.mean(logits)
loss.backward()
opt.step()
opt.clear_grad()
4.2 张量并行
保证数学上正确的前提下,将组网中的参数切分到不同的设备上,达到降低单个计算设备上的显存消耗的目的,用户要显示标记组网中参数的切分方式。
# 启动脚本:
# python3 -m paddle.distributed.launch --device=0,1,2,3 train.py
mesh = dist.ProcessMesh([0, 1, 2, 3], dim_names=['x'])
class MlpModel(paddle.nn.Layer):
def __init__(self):
super(MlpModel, self).__init__()
# 标记参数为切分状态,w0 沿 1 维切分
self.w0 = dist.shard_tensor(
self.create_parameter(shape=[1024, 4096]),
mesh, [dist.Shard(1)])
# w1 沿 0 维切分
self.w1 = dist.shard_tensor(
self.create_parameter(shape=[4096, 1024]),
mesh, [dist.Shard(0)])
def forward(self, x):
y = paddle.matmul(x, self.w0)
z = paddle.matmul(y, self.w1)
return z
此时x输入后,会根据此时参数的切分状态也进行切分,分别在不同设备上计算,每个设备上的值都是partial状态,最后各个卡结果进行sum得到全局的结果。
4.3 流水并行
流水并行,将模型的不同层放到不同的计算设备,降低单个设备的显存消耗。同时使用流水并行策略,可以一边输入数据一遍训练,节省训练时间。
# 启动脚本:
# python3 -m paddle.distributed.launch --device=0,1,2,3,4,5,6,7 train.py
mesh0 = dist.ProcessMesh([0, 1, 2, 3], dim_names=['x'])
mesh1 = dist.ProcessMesh([4, 5, 6, 7], dim_names=['x'])
class MlpModel(paddle.nn.Layer):
def __init__(self):
super(MlpModel, self).__init__()
self.w0 = dist.shard_tensor(
self.create_parameter(shape=[1024, 4096]),
mesh0, [dist.Replicate()])
self.w1 = dist.shard_tensor(
self.create_parameter(shape=[4096, 1024]),
mesh1, [dist.Replicate()])
def forward(self, x):
y = paddle.matmul(x, self.w0)
# 重切分,将 stage0 上的中间计算结果传输给 stage1
y = dist.reshard(y, mesh1, [dist.Replicate()])
z = paddle.matmul(y, self.w1)
return z
4.4 混合并行
分析可知,模型第一层和第二层分别在mesh0和mesh1两个进程网格上,mesh0做完的数据,要经过reshard给到mesh1。
mesh0 = [ mesh1 =[
[ 0 , 1][ 4 , 5 ]
[ 2, 3 ][ 6 , 7 ]
] ]
1.首先看模型第一层的权重w0,此时在x维度上进行了复制,也就是[0,1]和[2,3]分别放了w1这个参数的全部值,紧接着在y的维度上做了dist.shard(1),也就是对于[0,1]这一维网格,0,1分别放了w0的部分数据,[2,3]也同理,所以数据要在[0,1]和[2,3]两个网格间做数据并行即在x维做数据并行,mesh1同理(只不过是在y维做数据并行)
2.紧接着看一下输入,dist.shard_tensor(x, mesh0, [dist.Shard(0), dist.Replicate()]);,首先在x维度切分,在此处,x的形状是[batch_size, seq_len, hidden_size],batch_size等于2,也就是将x分为两份数据,紧接着在y维,分别给到[0,1]和[2,3],紧接着在y维度做Replicate,例如[0,1]这一个进程组,传入到[0,1]组的x的数据就复制两份分别给到0和1,紧接着做乘法运算,两个设备都是partial数据,再经过sum得到全局结果,即得到[0,1]的y,而[0,1]和[2,3]的y会自动再做reduce,然后得到最终的y
3.接下来将y,reshard到mesh1进程网络上,并且同样是在batch_size部分切成两份数据,给到[4,5]和[6,7],而紧接着以[4,5]进程组举例,dist.shard(2),此时processmesh对应[4,5],此时相当于dist.Replicate(),因此相当于把数据复制两份分别给设备4,5,然后再进行计算,同样4,5上面计算的结果都是partial状态的,要经过sum,最后[4,5]和[6,7]的数据再进行reduce,如paddle.mean,得到全局的dist_tensor——z。
# 启动脚本:
# python3 -m paddle.distributed.launch --device=0,1,2,3,4,5,6,7 train.py
import paddle
import paddle.distributed as dist
from paddle.io import BatchSampler, DataLoader, Dataset
import numpy as np
mesh0 = dist.ProcessMesh([[0, 1], [2, 3]], dim_names=['x', 'y']) # 创建进程网格
mesh1 = dist.ProcessMesh([[4, 5], [6, 7]], dim_names=['x', 'y']) # 创建进程网格
class RandomDataset(Dataset):
def __init__(self, seq_len, hidden, num_samples=100):
super().__init__()
self.seq_len = seq_len
self.hidden = hidden
self.num_samples = num_samples
def __getitem__(self, index):
input = np.random.uniform(size=[self.seq_len, self.hidden]).astype("float32")
return input
def __len__(self):
return self.num_samples
class MlpModel(paddle.nn.Layer):
def __init__(self):
super(MlpModel, self).__init__()
self.w0 = dist.shard_tensor(
self.create_parameter(shape=[1024, 4096]),
mesh0, [dist.Replicate(), dist.Shard(1)]) # 模型并行,列切
self.w1 = dist.shard_tensor(
self.create_parameter(shape=[4096, 1024]),
mesh1, [dist.Replicate(), dist.Shard(0)]) # 模型并行,行切
def forward(self, x):
dist.shard_tensor(x, mesh0, [dist.Shard(0), dist.Replicate()])
y = paddle.matmul(x, self.w0)
y = dist.reshard(y, mesh1, [dist.Shard(0), dist.Shard(2)]) #流水线并行
z = paddle.matmul(y, self.w1)
return z
model = MlpModel()
dataset = RandomDataset(128, 1024)
sampler = BatchSampler(
dataset,
batch_size=2,
)
dataloader = DataLoader(
dataset,
batch_sampler=sampler,
)
dataloader = dist.shard_dataloader(dataloader, meshes=[mesh0, mesh1], shard_dims='x')
opt = paddle.optimizer.AdamW(learning_rate=0.001, parameters=model.parameters())
opt = dist.shard_optimizer(opt)
for step, inputs in enumerate(dataloader):
data = inputs
logits = model(data)
loss = paddle.mean(logits)
loss.backward()
opt.step()
opt.clear_grad()
5.数据切分只有一个维度的记录
代码1:(shard为0)
import paddle
import paddle.distributed as dist
mesh = dist.ProcessMesh([0,1], dim_names=['x'])
dense_tensor = paddle.to_tensor([[1,2,3],
[4,5,6]
])
placements = [dist.Shard(0)]
dist_tensor = dist.shard_tensor(dense_tensor, mesh, placements)
print(1111111111111111,dist_tensor._local_value())

代码2:(shard为1)
import paddle
import paddle.distributed as dist
mesh = dist.ProcessMesh([0,1], dim_names=['x'])
dense_tensor = paddle.to_tensor([[1,2,3],
[4,5,6]
])
placements = [dist.Shard(1)]
dist_tensor = dist.shard_tensor(dense_tensor, mesh, placements)
print(1111111111111111,dist_tensor._local_value())

代码3:(shard为2)
import paddle
import paddle.distributed as dist
mesh = dist.ProcessMesh([0,1], dim_names=['x'])
dense_tensor = paddle.to_tensor([[1,2,3],
[4,5,6]
])
placements = [dist.Shard(2)]
dist_tensor = dist.shard_tensor(dense_tensor, mesh, placements)
print(1111111111111111,dist_tensor._local_value())

(shard为3以上直接hang住)
6.reshard记录
1.partial 转 replicate
import paddle
import paddle.distributed as dist
mesh = dist.ProcessMesh([0, 1], dim_names=["x"])
# dense tensor
a = [[1,2,3],
[4,5,6]
]
# distributed tensor
d_tensor = dist.shard_tensor(a, mesh, [dist.Partial()])
print(d_tensor)
out_d_tensor = dist.reshard(d_tensor, mesh, [dist.Replicate()])
print(out_d_tensor)

2.Shard(0) 转 replicate
import paddle
import paddle.distributed as dist
mesh = dist.ProcessMesh([0, 1], dim_names=["x"])
# dense tensor
a = [[1,2,3],
[4,5,6]
]
# distributed tensor
d_tensor = dist.shard_tensor(a, mesh, [dist.Shard(0)])
print(d_tensor)
out_d_tensor = dist.reshard(d_tensor, mesh, [dist.Replicate()])
print(out_d_tensor)

7.BatchSampler, DataLoader, Dataset记录
# 运行方式: python train.py
import numpy as np
import paddle
from paddle.io import BatchSampler, DataLoader, Dataset
class RandomDataset(Dataset):
def __init__(self, seq_len, hidden, num_samples=100):
super().__init__()
self.seq_len = seq_len
self.hidden = hidden
self.num_samples = num_samples
def __getitem__(self, index):
input = np.random.uniform(size=[self.seq_len, self.hidden]).astype("float32")
label = np.random.uniform(size=[self.seq_len, self.hidden]).astype('float32')
return (input, label)
def __len__(self):
return self.num_samples
class MlpModel(paddle.nn.Layer):
def __init__(self):
super(MlpModel, self).__init__()
self.w0 = self.create_parameter(shape=[1024, 4096])
self.w1 = self.create_parameter(shape=[4096, 1024])
def forward(self, x):
y = paddle.matmul(x, self.w0)
z = paddle.matmul(y, self.w1)
return z
with paddle.LazyGuard():
model = MlpModel()
for p in model.parameters():
p.initialize()
dataset = RandomDataset(128, 1024)
sampler = BatchSampler(
dataset,
batch_size=4,
)
dataloader = DataLoader(
dataset,
batch_sampler=sampler,
)
opt = paddle.optimizer.AdamW(learning_rate=0.001, parameters=model.parameters())
loss_fn = paddle.nn.MSELoss()
for step, (inputs, labels) in enumerate(dataloader):
logits = model(inputs)
loss = loss_fn(logits, labels)
loss.backward()
opt.step()
opt.clear_grad()
print(f"max_memory_reserved = {paddle.device.cuda.max_memory_reserved() / 1e6 : .2f} MB") # 178.28 MB
RandomDataset用来随机生成数据,seq_len为序列长度,hidden为特征维度,num_samples为生成多少个数据,BatchSampler用来将生成的这么多个数据进行分组,每组的数据量=batch_size ,当最后一组数据不够分,默认保留,注意,BatchSampler的分组,一个组中保存的不是这一组的数据,而是数据的index,而DataLoader 会根据 BatchSampler 配置好批次的索引和数据的读取顺序,DataLoader利用BatchSampler 划分的index组,来迭代读取数据,但定义的时候,不会加载数据。它只是创建了一个迭代器,准备好在训练过程中读取数据。而每次for循环迭代的时候,才是真正访问随机创建数据的时候。