Save_load问题追踪记录
1.当前保存的文件状态
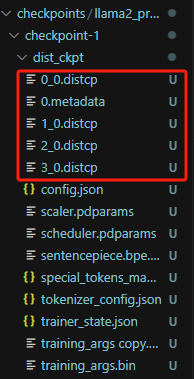
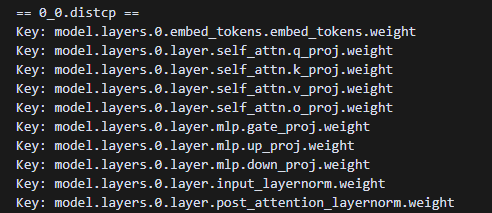
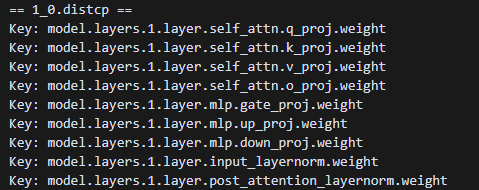
当前冷启动保存的模型参数是分片状态的模型参数,多个distcp对应不同rank。
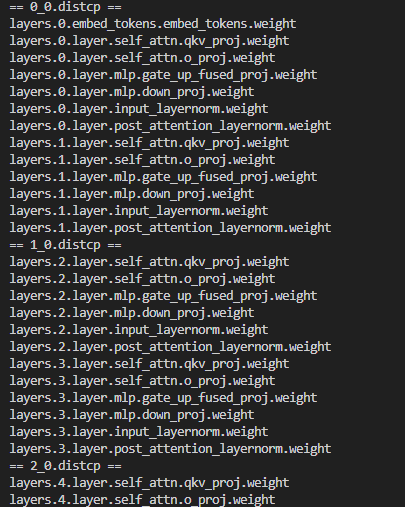
distcp保存的参数
翻阅之前的文档,我认为这里应该还要保存opt对应的参数文件才对。
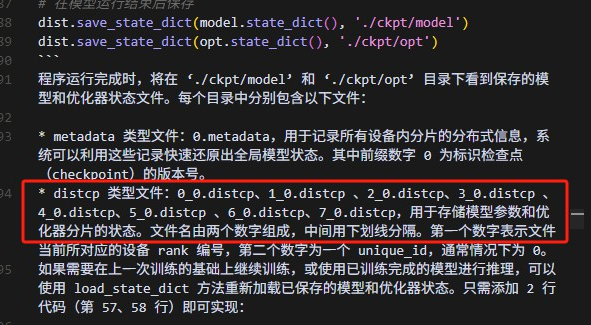
distcp相关文档
同时热启动的时候也会警告,这些参数在checkpoint的权重文件中没有找到。
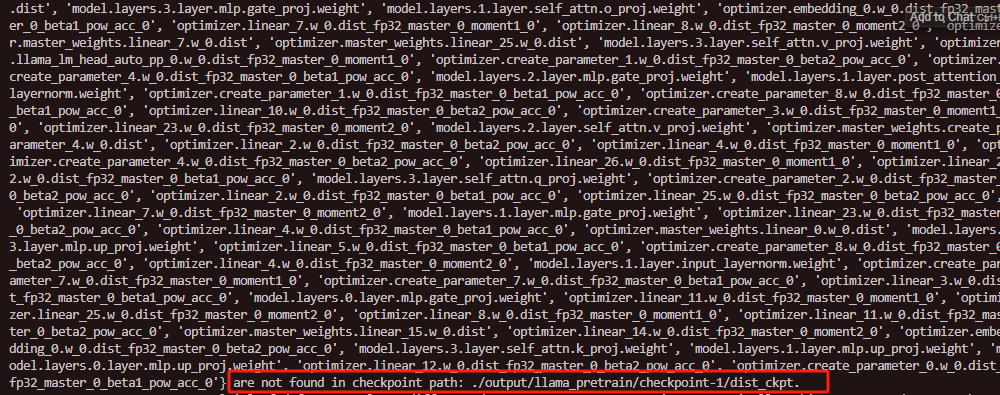
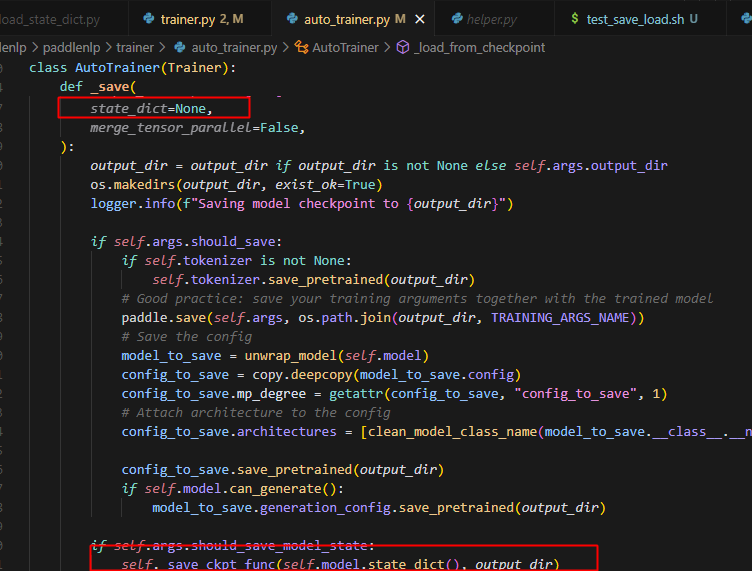
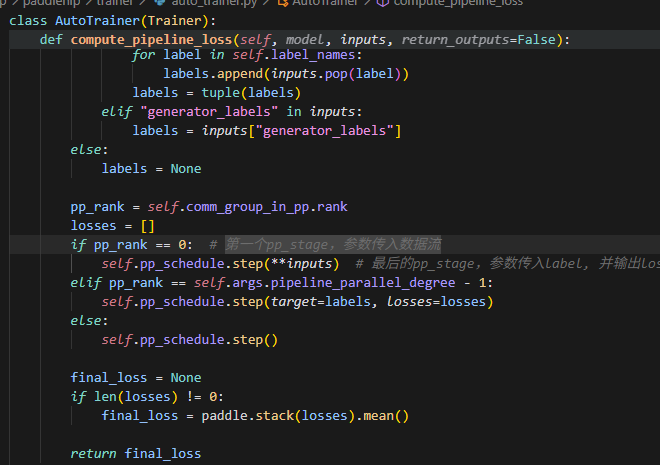
2.保存模型的相关代码
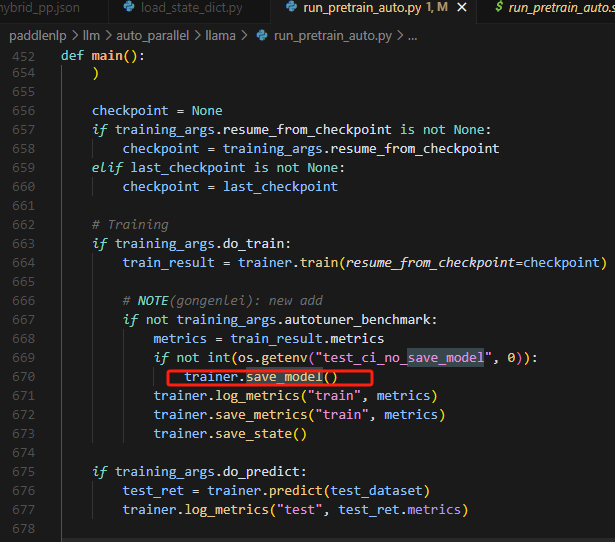
这个save_model只控制输出文件是否保存最终模型训练文件,不控制checkpoint是否保存模型训练文件。
3.checkpoint的保存
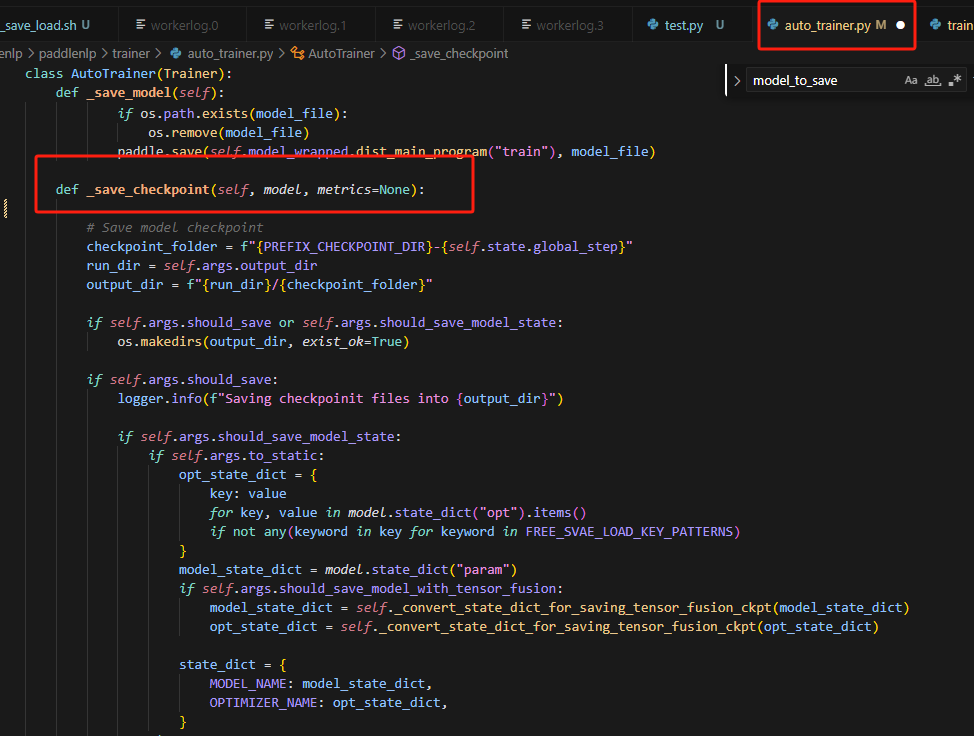
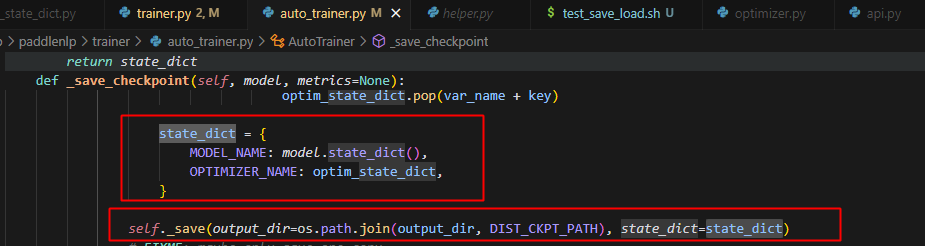
主要_save_checkpoint函数控制,目前存在问题:
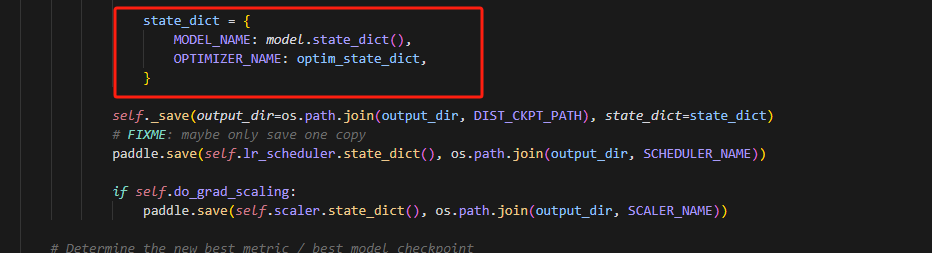
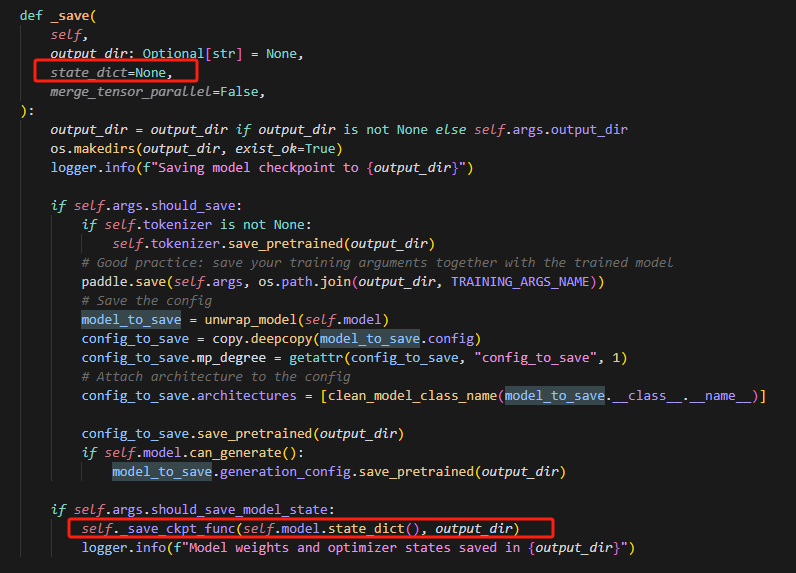
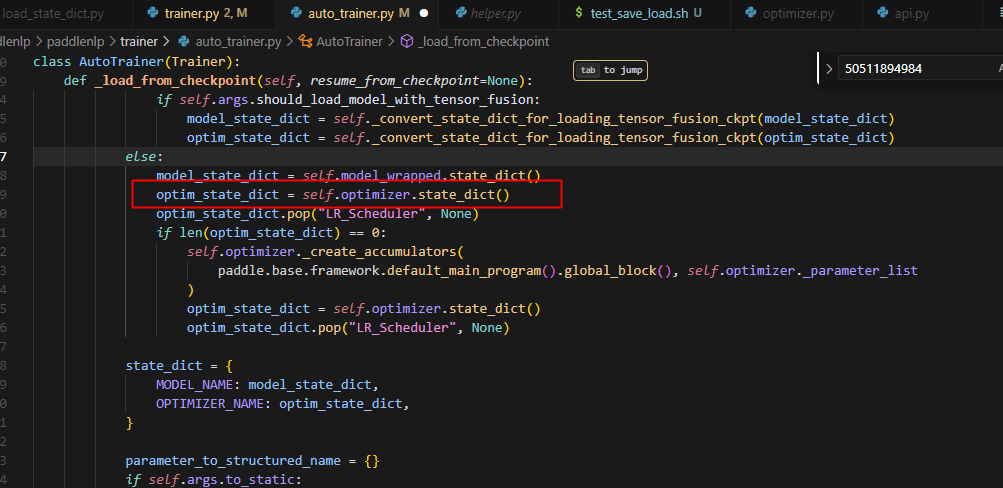
虽然state_dict传入了,但是没有用上,做如下修改,即可:

4.精度对齐的flag设置
export FLAGS_cudnn_deterministic=True
export FLAGS_embedding_deterministic=1
5.load需要添加参数
# 动半/静半 load 的时候添加参数
--resume_from_checkpoint "dynamic_output1/checkpoint-3"
6.checkpoint数据文件记录


.metadata是包含所有参数的key但是不包含value,实际的value都在权重文件里,例如.distcp文件中。
7.load_state_dict函数记录
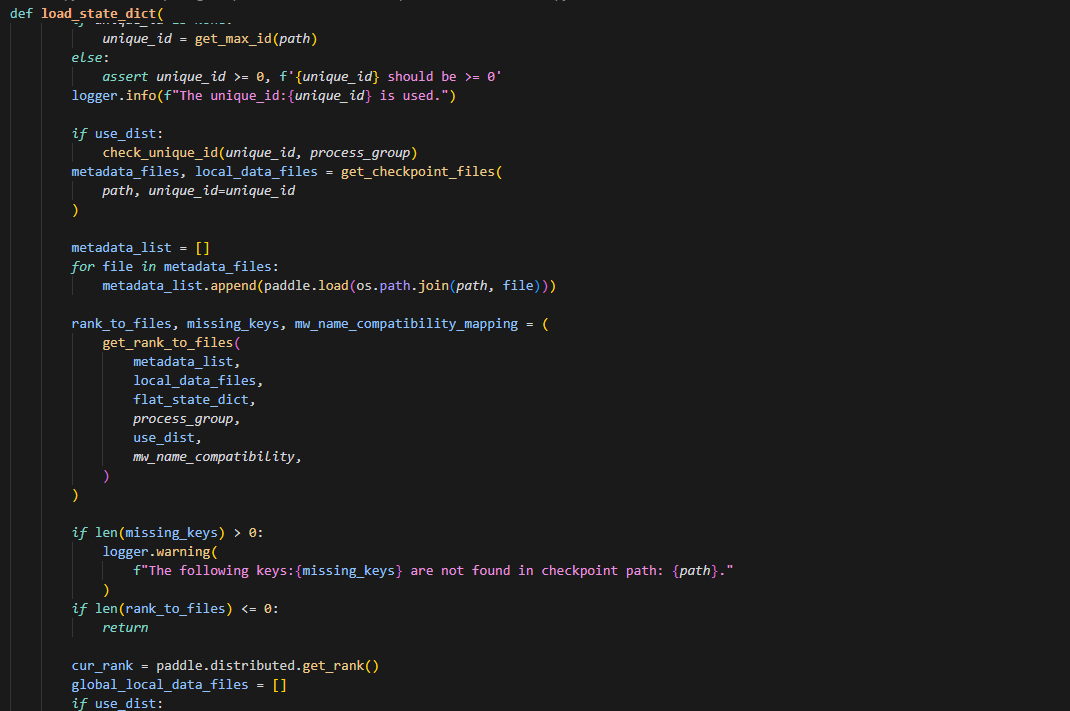
首先会使用get_checkpoint_files获取 metadata_files, local_data_files两个文件,两个文件的作用在6中解释了,紧接着根据metadata_files, local_data_files以及flat_state_dict(即展开的初始化的model和opt的权重参数字典),调用get_rank_to_files去获得 rank_to_files, missing_keys, mw_name_compatibility_mapping三个参数列表,先看一下get_rank_to_files函数,再解读这三个参数。
def get_rank_to_files(
metadata_list,
local_data_files,
state_dict,
process_group,
use_dist,
mw_name_compatibility=True,
):
"""
Get the mapping of rank to its accessible files.
"""
# The necessary files to be read
tensor_key_list = []
necessary_files = []
mw_name_compatibility_mapping = {}
for metadata in metadata_list:
for local_tensor_index, file_name in metadata.storage_metadata.items():
assert (
local_tensor_index not in tensor_key_list
), f"Duplicate tensor_key:{local_tensor_index} found. Check whether the metadata."
tensor_key_list.append(local_tensor_index.tensor_key)
if local_tensor_index.tensor_key in state_dict:
necessary_files.append(file_name)
all_necessary_files = []
if use_dist:
paddle.distributed.all_gather_object(
all_necessary_files, necessary_files, process_group
)
else:
all_necessary_files.append(necessary_files)
global_necessary_files = [
file for files in all_necessary_files for file in files
]
global_necessary_files_set = set(global_necessary_files)
if len(global_necessary_files_set) <= 0:
logger.warning(
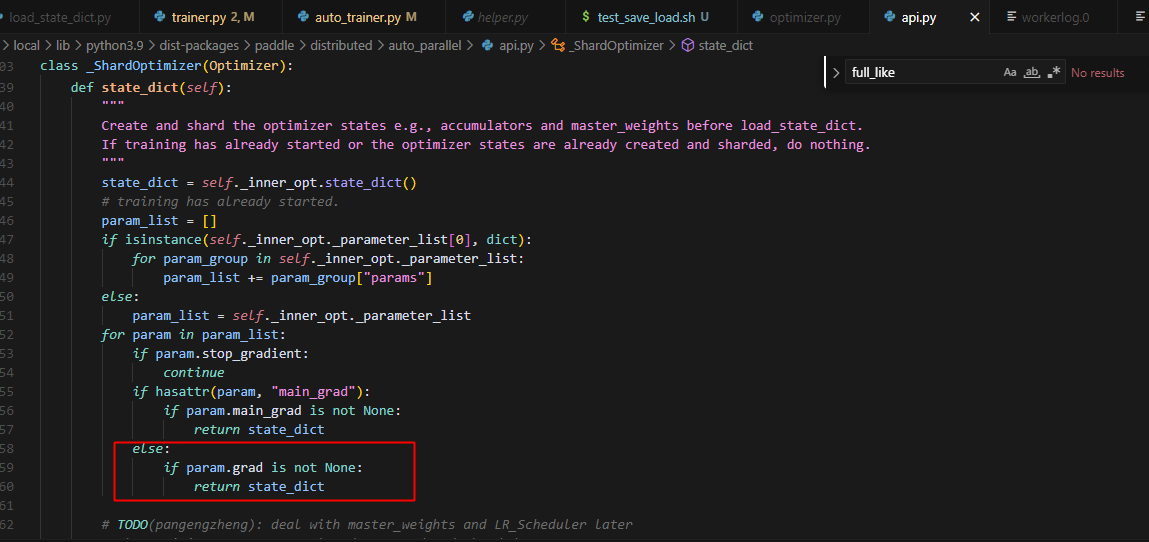
"No necessary data files found in the checkpoint directory. Please check the metadata."
)
missing_keys = set(state_dict.keys())
return {}, missing_keys, mw_name_compatibility_mapping
# allgather all accessible files
global_data_files = []
if use_dist:
paddle.distributed.all_gather_object(
global_data_files, local_data_files, process_group
)
else:
global_data_files.append(local_data_files)
tmp = []
for files in global_data_files:
tmp += files
global_data_files_set = set(tmp)
logger.debug(
f"necessary_data_files_set:{global_necessary_files_set}, global_data_files_set:{global_data_files_set}"
)
# check necessary files in global_data_files
assert (
global_data_files_set & global_necessary_files_set
== global_necessary_files_set
), f"The checkpoint files are not complete. Please check the checkpoint directory. global_data_files_set:{global_data_files_set}, necessary_data_files_set:{global_necessary_files_set}"
missing_keys = set(state_dict.keys()) - set(tensor_key_list)
if len(missing_keys) > 0:
if mw_name_compatibility:
mw_name_compatibility_mapping = _modify_mw_name_for_compatibility(
state_dict, missing_keys, tensor_key_list
)
if len(missing_keys) > 0:
logger.warning(
f"Missing keys:{missing_keys}, check whether the checkpoint is complete."
)
else:
logger.warning(
f"Missing keys:{missing_keys}, check whether the checkpoint is complete."
)
rank_to_files = {}
for rank, need_files in enumerate(all_necessary_files):
seen = set()
unique_need_files = [
f for f in need_files if not (f in seen or seen.add(f))
]
rank_to_files[rank] = unique_need_files
logger.debug(f"mapping rank_to_files:{rank_to_files}")
return rank_to_files, missing_keys, mw_name_compatibility_mapping
metadata文件记录了所有数据的key,没有value,并记录了这个数据对应保存的文件,当metadata中包含state_dict中的key时,说明此时需要将checkpoint中保存的数据加载到模型参数,才会把这个key对应的文件保存到rank_to_files,missing_keys即state_idct中的key去掉checkpoint中权重文件里面和state_dict能够匹配的key,不过注意在此之前,missing_keys还会被_modify_mw_name_for_compatibility函数处理,函数如下:
def _modify_mw_name_for_compatibility(
state_dict, missing_keys, tensor_key_list
):
"""
Adjust the master weight name within the optimizer's state_dict to ensure compatibility between semi-automatic parallel execution in both dynamic and static graph modes.
Args:
state_dict(Dict[str, paddle.Tensor]): The state_dict to load. It will be modified inplace after loading.
missing_keys(Set[str]): A set of keys that are expected to be loaded but are missing.
tensor_key_list(List[str]): A list of tensor keys from the source checkpoint (ckpt).
"""
compatibility_set = set()
mw_name_compatibility_mapping = {}
compatibility_key = None
for missing_key in missing_keys:
parts = missing_key.split(".")
# Determine compatibility key based on naming style
if "master_weights" in parts:
parts.remove("master_weights")
compatibility_key = ".".join(parts) + "_fp32_master_0"
elif parts[-1].endswith("_fp32_master_0"):
parts[-1] = parts[-1].replace("_fp32_master_0", "")
parts.insert(1, "master_weights")
compatibility_key = ".".join(parts)
if compatibility_key in tensor_key_list:
logger.info(
f"Modify master weights {missing_key} -> {compatibility_key}"
)
compatibility_set.add(missing_key)
mw_name_compatibility_mapping[missing_key] = compatibility_key
state_dict[compatibility_key] = state_dict.pop(missing_key)
# update missing_keys
missing_keys -= compatibility_set
return mw_name_compatibility_mapping
这个函数主要是用来过滤missing_keys中由于静半和动半的不同命名规则导致有些键值对是一样的,但是由于命名不同导致不匹配进入missing_keys,在这里就会给其匹配上,并更新missing_keys。
8.热启动的时候,出现问题:
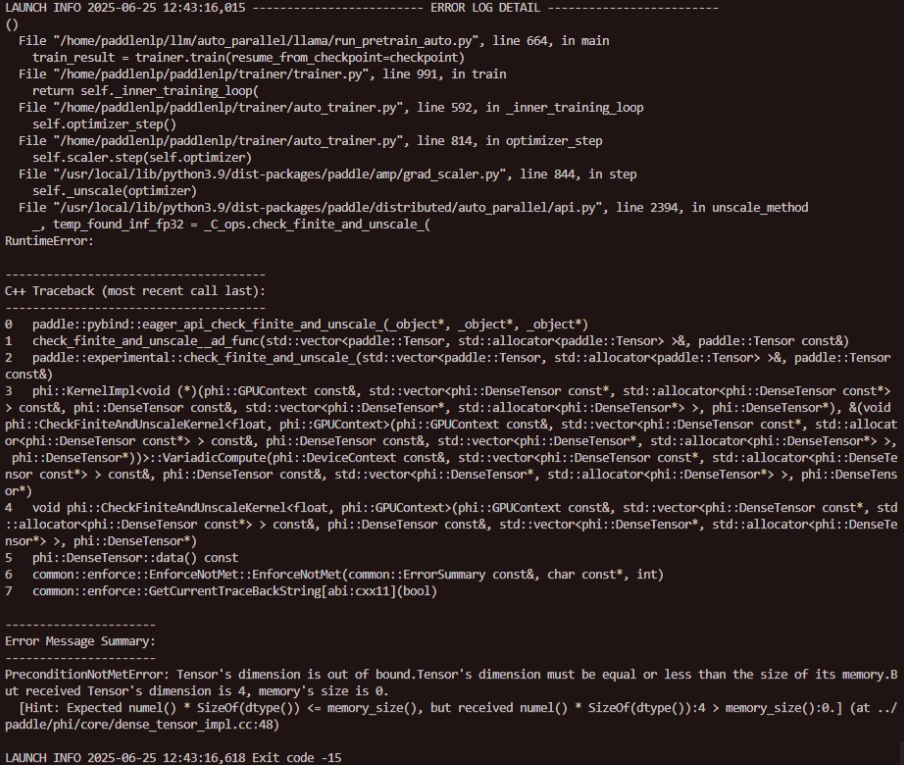
分析原因是非法访问空的tensor,追溯:
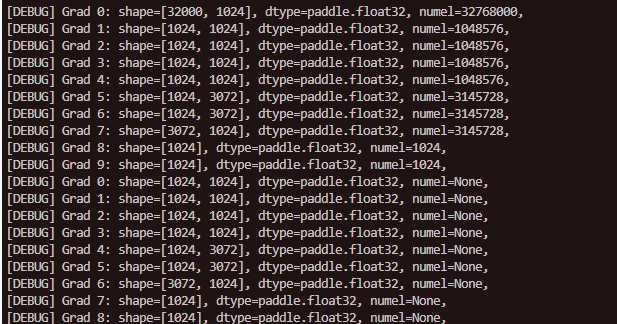
发现4pp的时候,每个rank会执行四次unscale_method方法,因为参数被分为了4组,分别在4个rank上,但是只有属于自己参数的时候,对应的grad才给分配了空间,正确初始化了,而非法对其他未初始化的grad调用C_ops.check_finite_and_unscale,就会报memory错误。
修改方法如下:
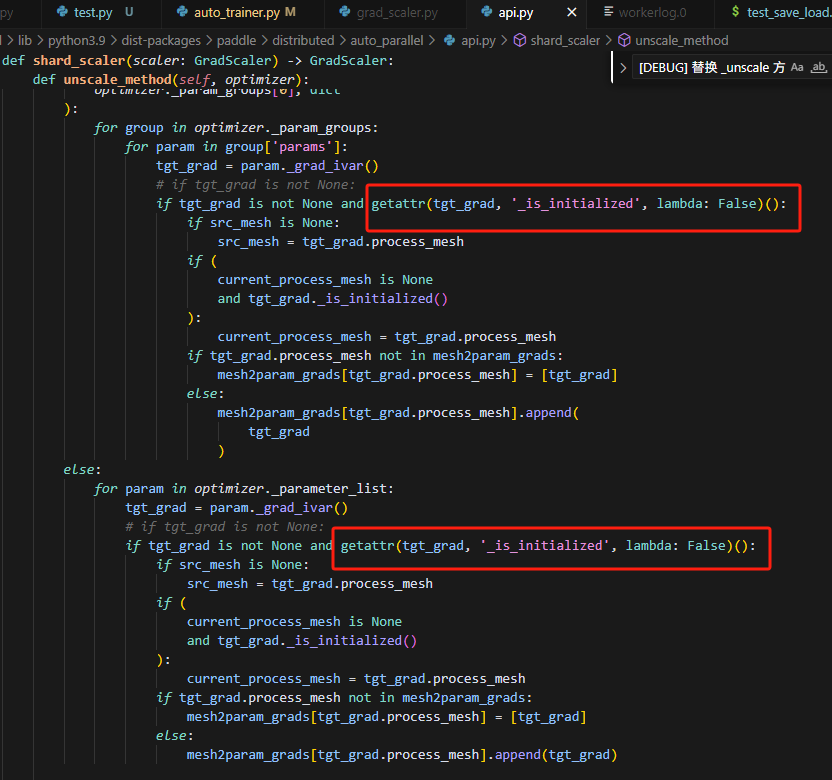
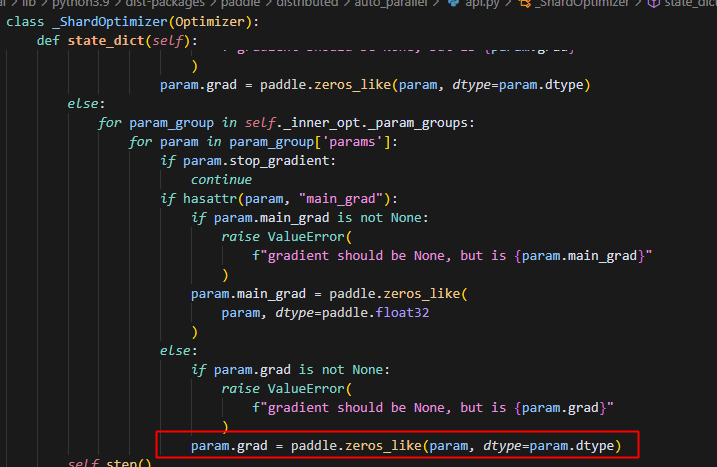
判断一下当前参数的grad是否被初始化,若不是当前rank处理的层,则grad不会被初始化,因此若grad未被初始化,则不添加到处理列表中。
![]()
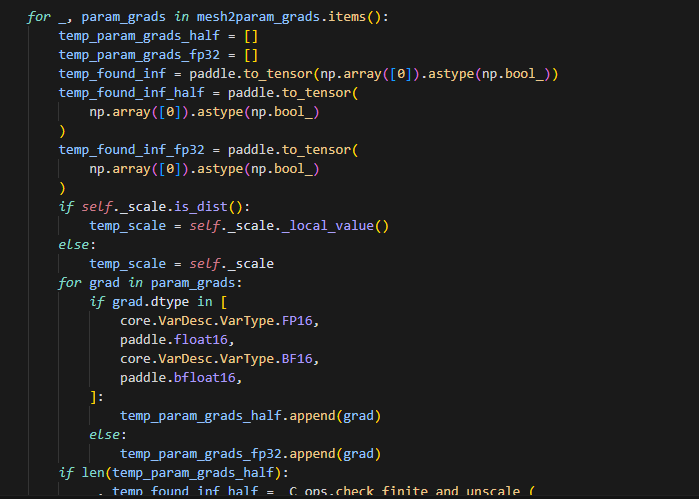
同时可以看到,这里主要处理两个情况的grad,一种是fp32,一种是半精度——包括f16和bf16;当这两个列表都为空时,则表示当前rank没有自身要处理的grad,则直接return即可。
9.MethodType方法替换
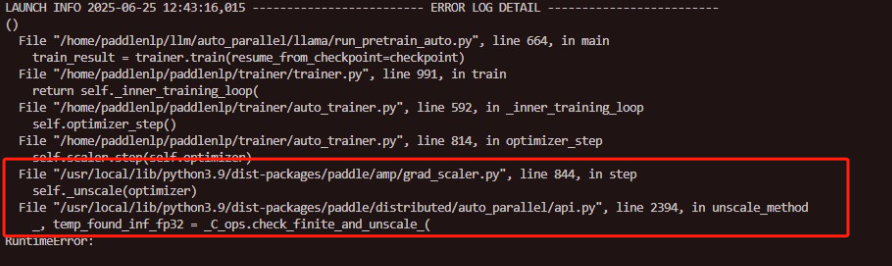
报错时,从grad_scaler.py跳转到了api.py,但是在grad_scaler.py中也实现了self.unscale()方法,导致笔者并不知道什么时候替换的这个方法,或者在哪里做的映射,经过查证发现,在shard_scaler下有一行替换代码,写明了替换。
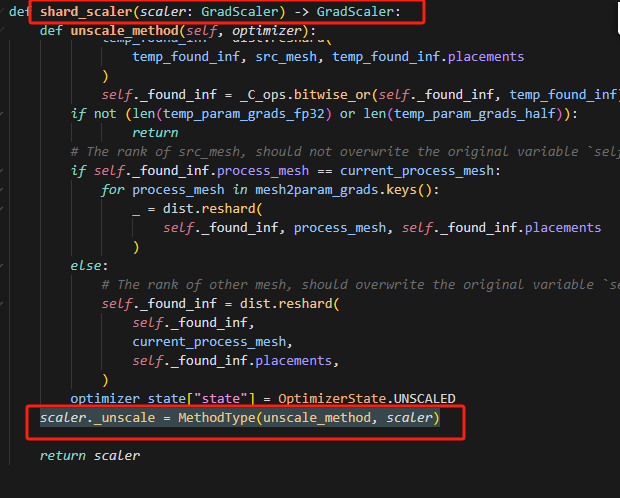
shard_scaler也仅仅是做了这一行替换,因为scaler也主要只是使用scaler,在内部实现分布式的方法。其中scaler._unsacle是要替换掉的方法,unscale_method是用来替换并使用的方法,scaler是一个对象实例。
10.Scaler使用
例如在FP16精度下,最小值约6.1e-5,最大值约6.5e4,如果loss太小,比如loss 1e-6,FP16无法表示,则需要乘以对应的scaling 因子放大loss,原来的loss为L,现在是loss_scaled*loss,反向传播的时候,所有梯度也都会乘以loss_scaled。
11.paddle.amp.decorate使用
实现自动混合精度(AMP)训练的核心入口之一。它的作用是根据用户配置,把模型和优化器“装饰”成支持混合精度训练的版本,并根据不同的 AMP 级别(如 O1、O2)自动处理参数类型、主权重、梯度等细节。
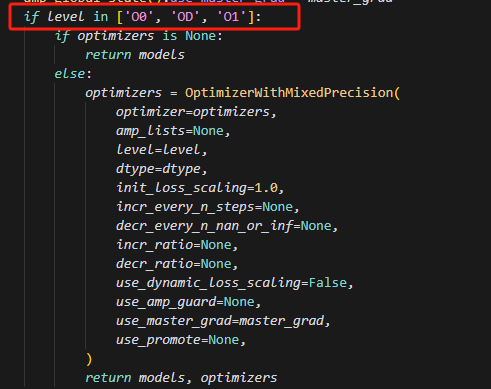
如图,当level不为02时,此时,要么仅仅对优化器设置多精度融合,模型仍然保持float32精度。
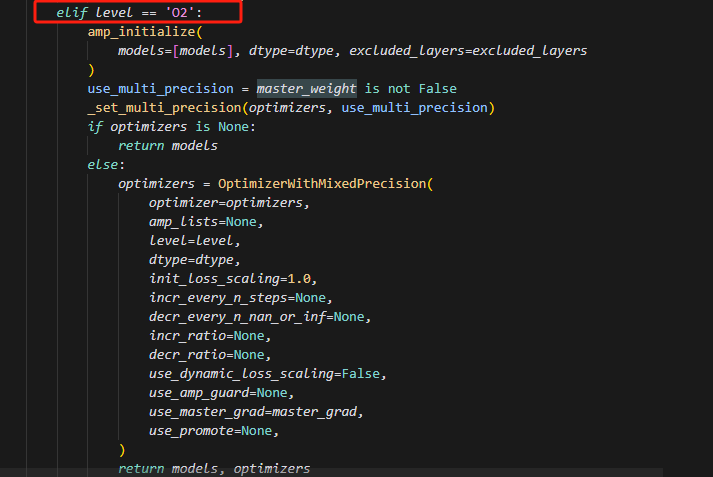
当level为02时,首先会对模型参数做精度转换,紧接着,若master_weight为False,则优化器内部维护的主权重不做多精度,仍为float32;若未设置,默认为None,或设置为True,则均做多精度;其中master_grad若设为True,则反向传播时,其做精度为float32的计算。
12.为什么把state_dict删掉,仍然能正常更新参数
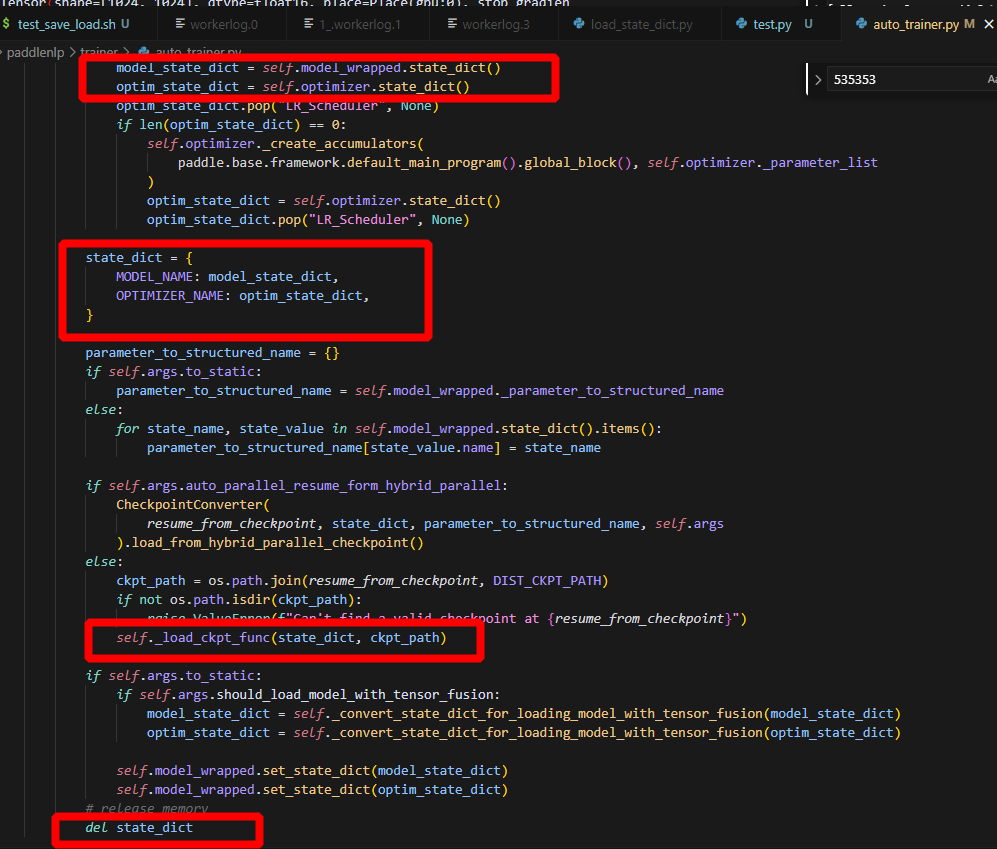
这里的model_state_dict和optim_state_dict虽然是创建了一个新的dict来存取self.model_wrapped.state_dict()和self.optimizer.state_dict()的键值对,但是对应的value是引用而不是深拷贝,因此,当在self._load_ckpt_func中改变这个value的值的时候,对应model和optimizer的参数也会对应改变,从而实现参数的改变。
13.optimizer分析
注意,optimizer中是不保存模型参数的,但是optimizer._parameter_list可以访问模型参数,parameter_list就是把传进来的model.parameter给放进来list中。
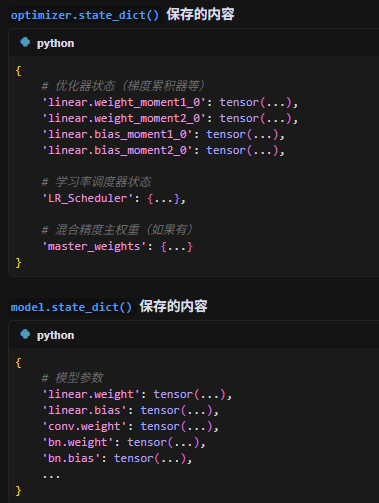
默认使用AdamW优化器
14.分析为什么冷启动不报错,但是热启动报错
记录不同点:
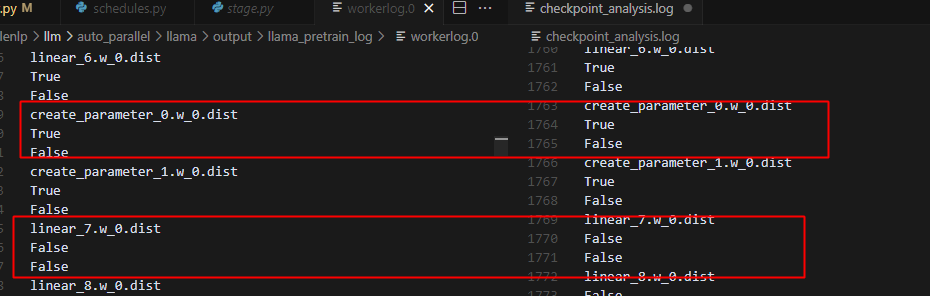
首次训练前数据的梯度状态不同
热启动时,参数的梯度是未定义的状态:
冷启动时,首次训练的参数梯度均定义了,且都为None:
定位原因:
![]()
热启动经过了这一步,导致self.optimizer._parameter_list从一开始的梯度全None,变为梯度未定义
optimizer的参数状态不同:
冷启动时,不在当前rank的模型层参数tensor是空的,shard到了其它rank上,同时梯度是None
热启动时,不在当前rank的模型层参数tensor是空的,shard到了其它rank上,但是梯度不为None。
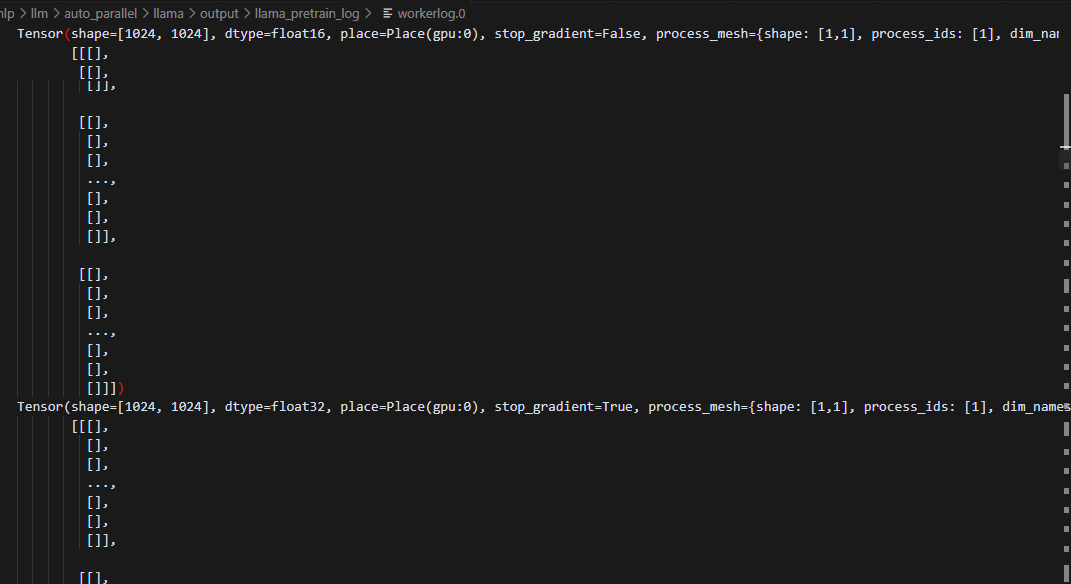
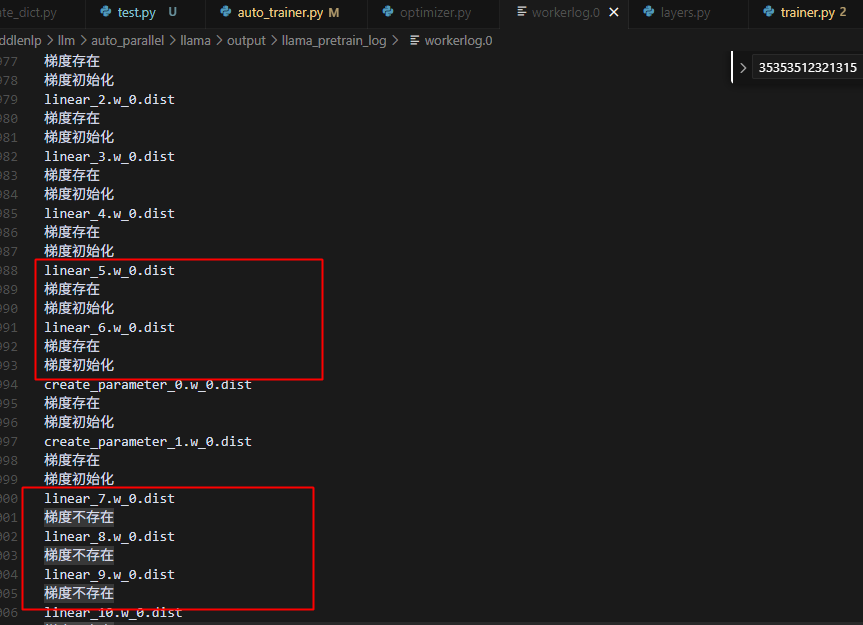
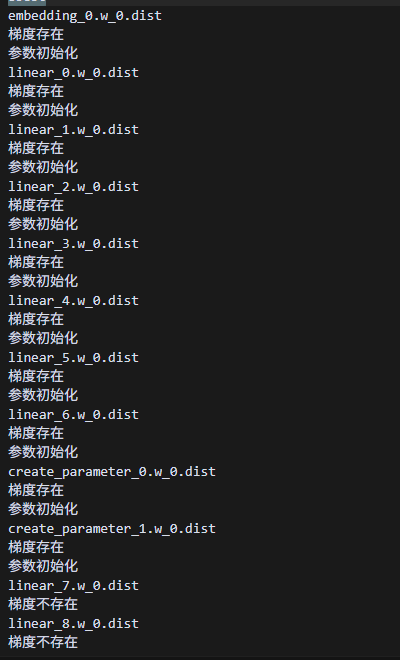
打印冷启动(1)、checkpoint数据(2)、热启动(3)的参数对比如下,可以看到checkpoint的参数是正常加载进去了的:
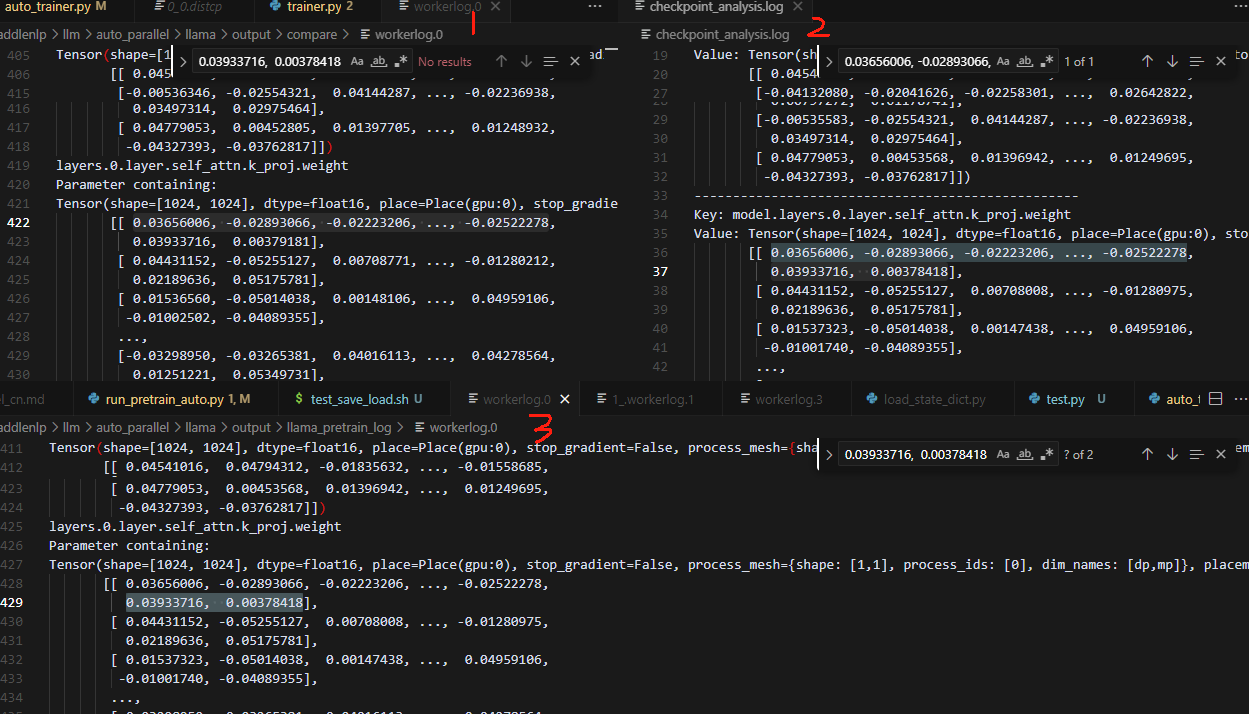
冷启动和热启动的两种情况下非本rank的参数的stop_gradient都是False(第一个bool表示是否初始化,第二个bool表示stop_gradient)
grad_ivar的具体实现:
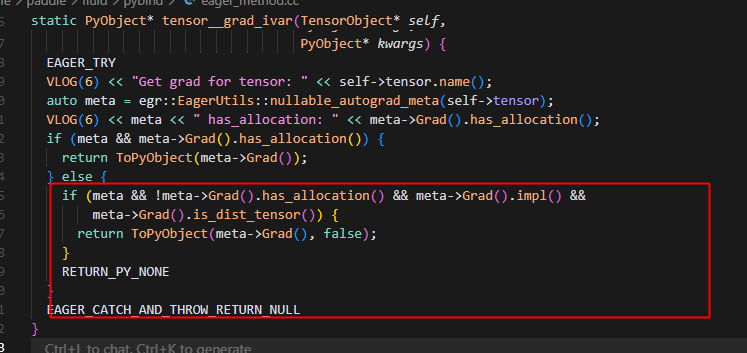
meta->Grad().impl() != nullptr // - 张量对象存在
meta->Grad().has_allocation() == flase // - 但内存未分配
热启动时:
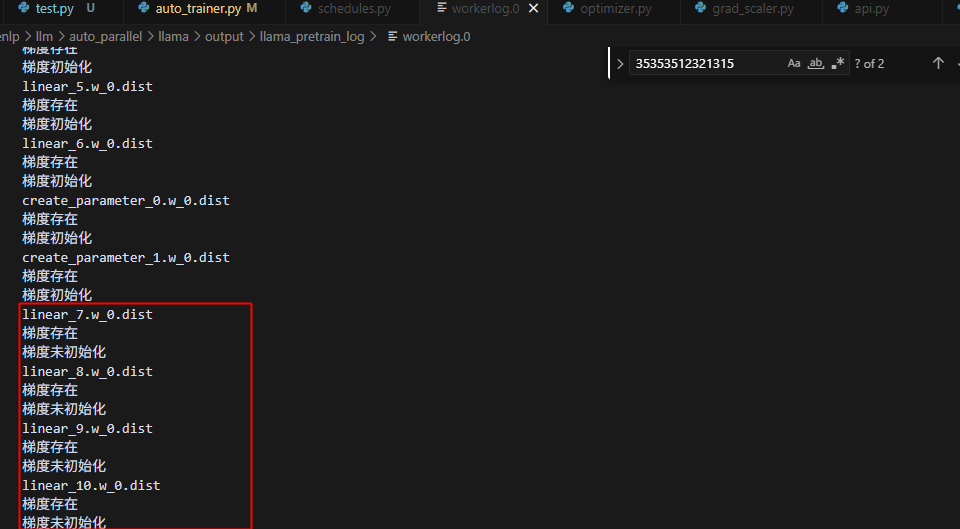
冷启动时:
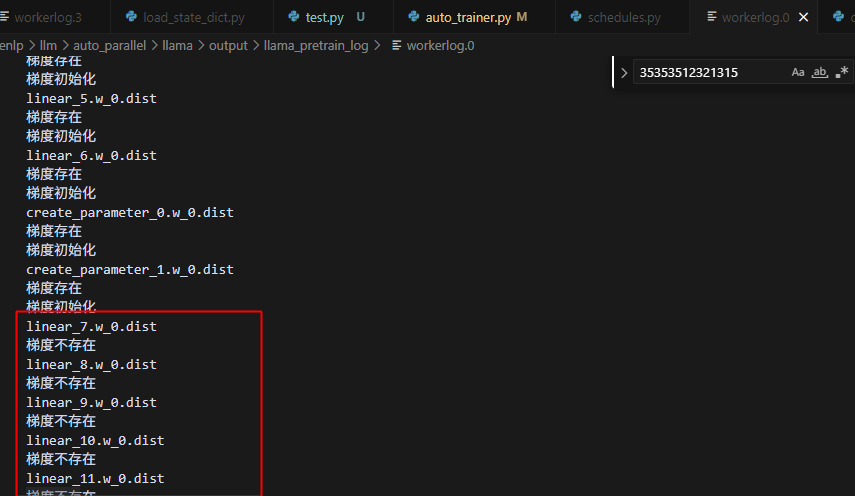
具体原因定位到:
以step3为例子:
热启动运行到这里,一行代码,实际执行了两次opt.state_dict,第一次全是梯度不存在,而第二次全是梯度存在,梯度未初始化:
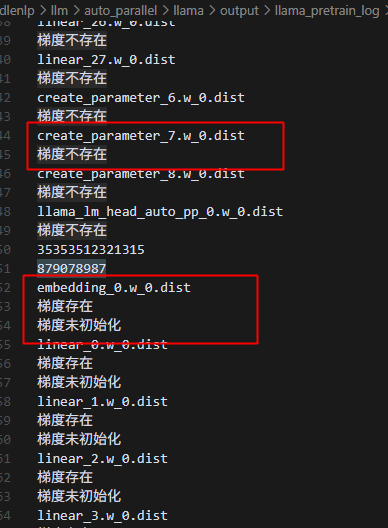
打印调用栈分析原因:
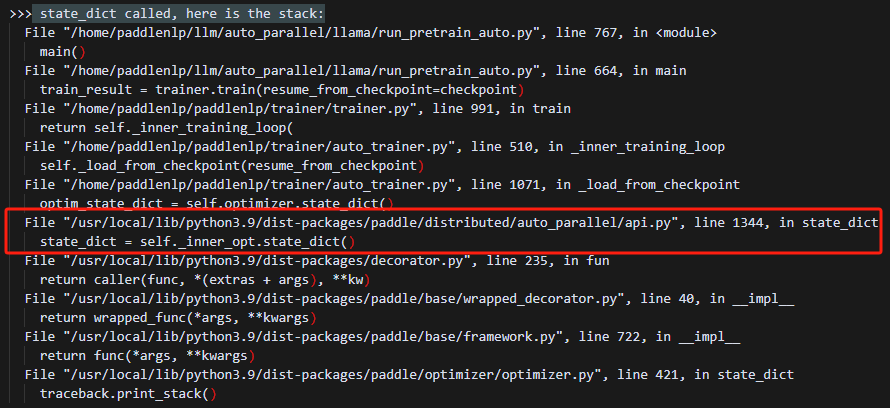
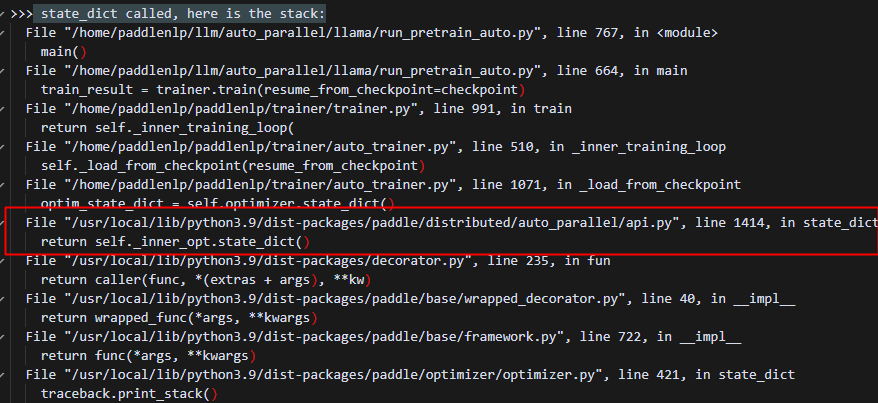
发现实际调用的是api中的state_dict:
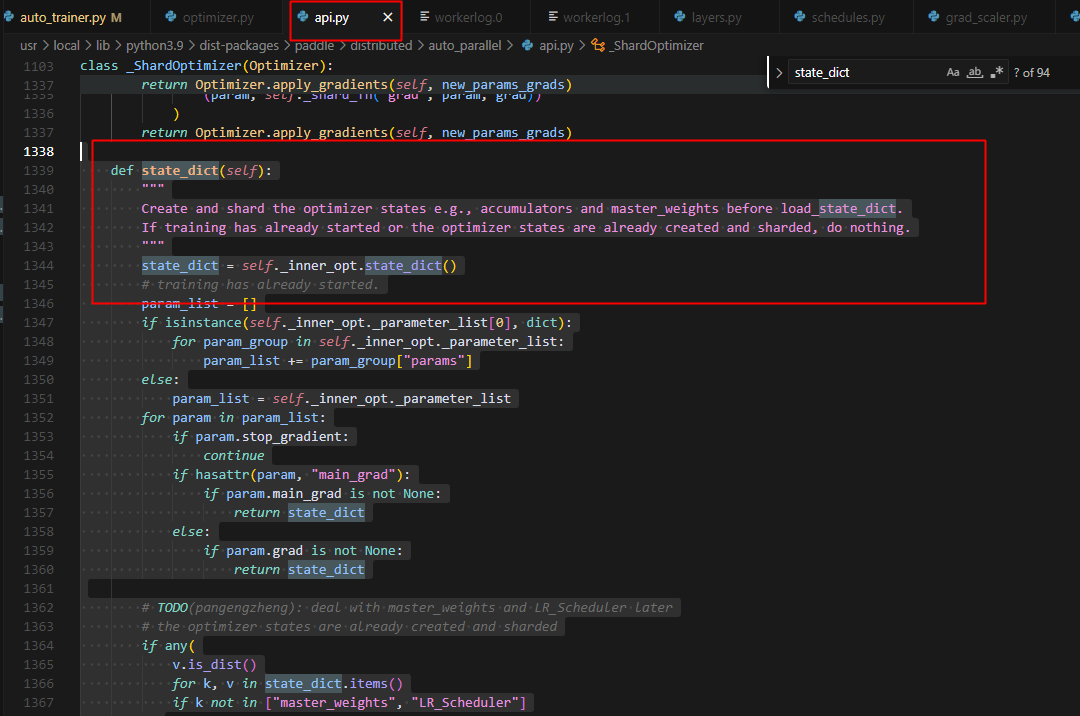
而冷启动,三步训练,每一步训练,都是本rank的梯度存在且初始化了,但非本rank的梯度不存在:
冷热启动都会走这一步:
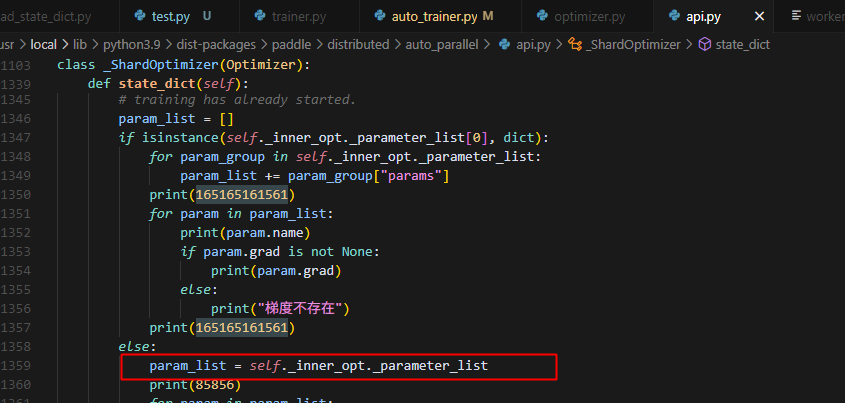
热启动的情况,因为所有参数都不存在梯度,因此导致在后面会触发初始化操作,就要fake对应的grad,导致所有的参数都有grad了,因为参数是有分布式属性的,所以grad创建时也具有分布式属性,所以不在本rank的参数,对应的梯度也是同样的状态,即梯度存在,但是未初始化:
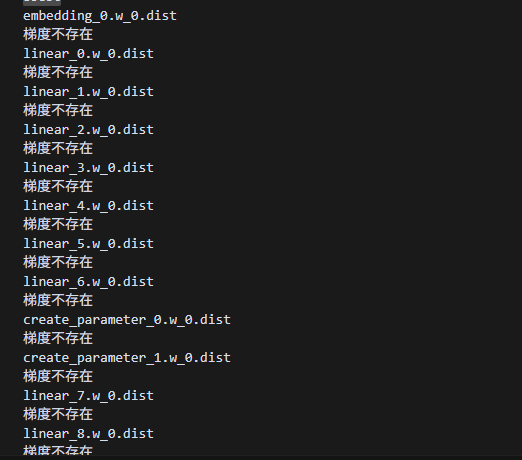
冷启动的情况,一开始获取的参数就是本rank的梯度存在,并且做了初始化,而非本rank的参数则没有梯度:
综上总结出了热启动load出错的根本原因:
问题1 热启动报异常访问内存:
报错直接原因是:
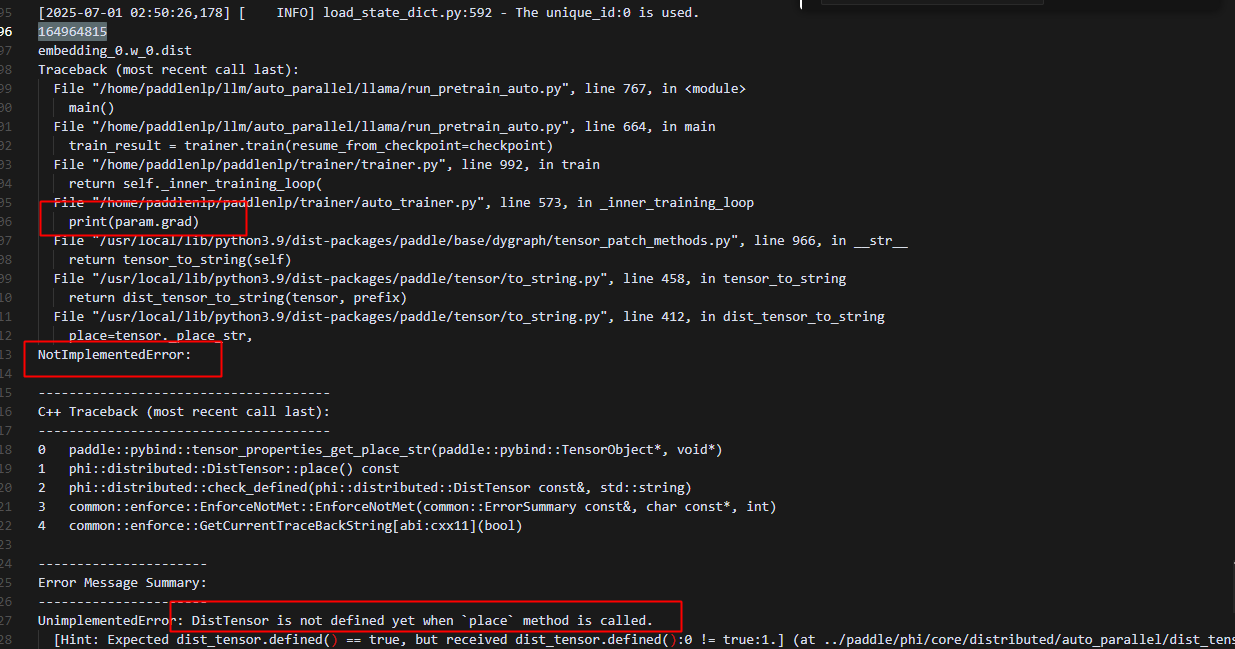
热启动的时候,在float16精度下(bf16也会如此),为了防止数据下溢,反向过程中,对loss和梯度做scale,在参数更新时,即opt阶段,需要做unscale将数据缩放回来,此时会调用auto_parallel.api中的unscale_method方法,在该方法中,只要param的grad不为None,就会被添加到处理列表中,而对于非本rank的梯度,此时处于定义了但未初始化的状态,因此是未分配内存的,此时访问这些grad则会报非法访问的内存错误。
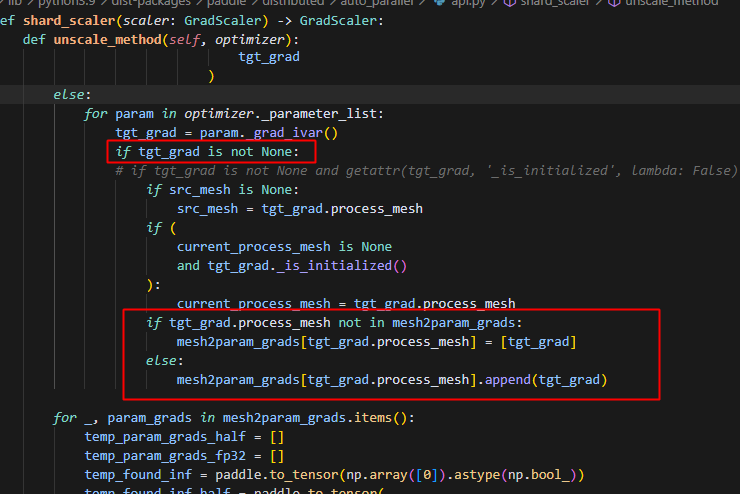
问题2 热启动时参数未正确加载(不会报错,会直接用原始模型参数做初始化训练,但无法正确加载checkpoint)
报错直接原因是:
在save的时候,没有用到state_dict,而是直接保存了模型参数,未保存optimizer的参数,一方面保存的checkpoint中没有optimizer参数的信息,另一方面,导致加载时,key的名称对不上,以state_dict保存会有model.和optimizer.的前缀,后者没有。
追根溯源
1:为什么冷启动正常运行,而热启动报错?
冷启动和热启动,刚刚开始时,所有参数的梯度均为None;
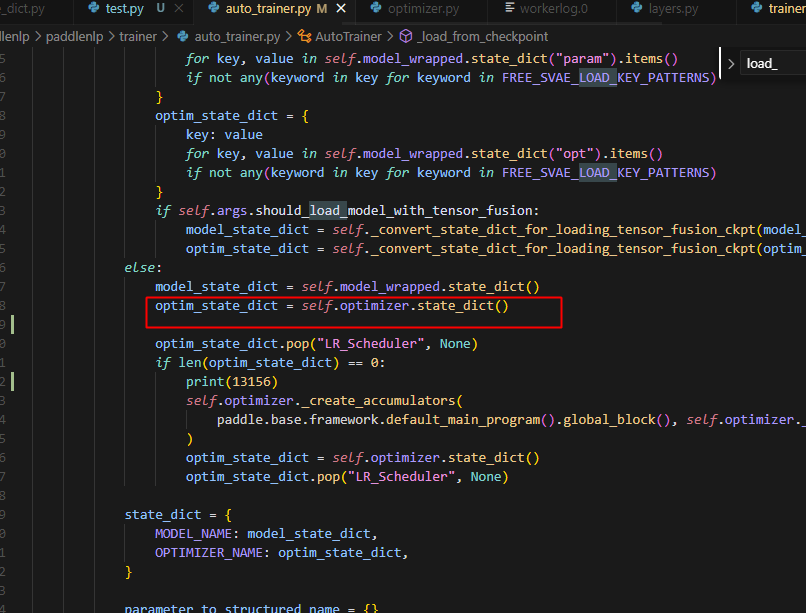
对于热启动而言,会调用_load_from_checkpoint方法,而在该方法中会首次访问self.optimizer.state_dict()方法,即对应auto_parallel.api中的state_dict`方法
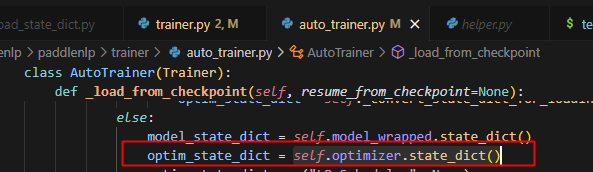
self.optimizer.state_dict()调用位置图
由于此时参数的梯度均为None,因此optimizer的状态会被判定为未正确创建,因此会经过以下处理:先给参数伪造一个梯度,然后调用一次 step,这样优化器就会自动初始化和切分所有需要的状态(其实这里的本意是在使用optimizer的时候,避免optimizer是一个未初始化的状态,然而此时实际只是想获取热启动时optimizer中保存的键,所以误触了此处的兜底逻辑)。因此,此时这里的逻辑,将所有参数的梯度做了初始化(注意由于懒启动,此时并没有实际分配内存),而后续,本rank的参数和梯度要参与计算,因此会初始化,分配内存,而其它rank的参数和梯度在本rank的状态就变成了,已定义但未初始化的状态(这里与冷启动不同,冷启动只定义了其它rank的状态,而其它rank的参数梯度均为None),因此在做unscale的时候,出现问题,具体反映在auto_parallel.api中的unscale_method方法,非本rank的梯度未被grad is None这个条件过滤,而它们都处于未分配内存的状态,访问时,就会导致内存的非法访问。
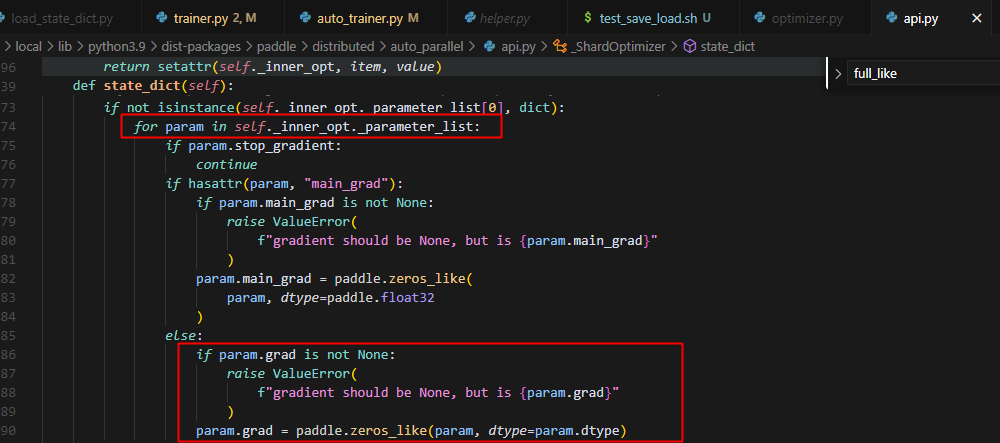
api中state_dict()的处理逻辑图
对于冷启动而言,是在_save_checkpint时才访问self.optimizer.state_dict()方法,所以不存在上述问题,并且param由于懒启动的原因,也是在计算时才初始化,并且初始化对应梯度,而非本rank的参数的梯度依旧保持为None,因此原来的处理逻辑能够正常运行。
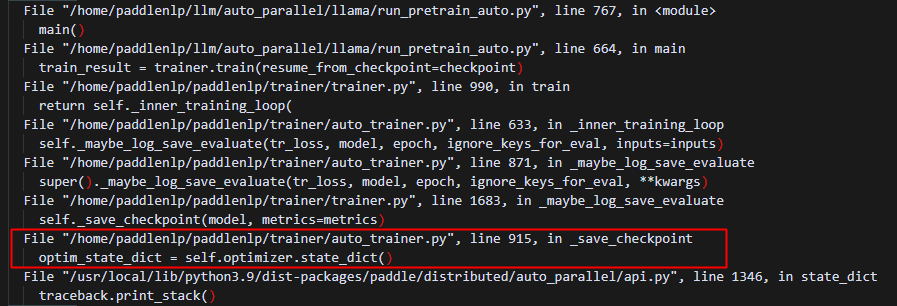
冷启动时optimizer.state_dict的调用栈
2:optimizer保存的信息状态?
每个rank只有自己的optimizer的信息,不过命名是全局视角的,不会重命名
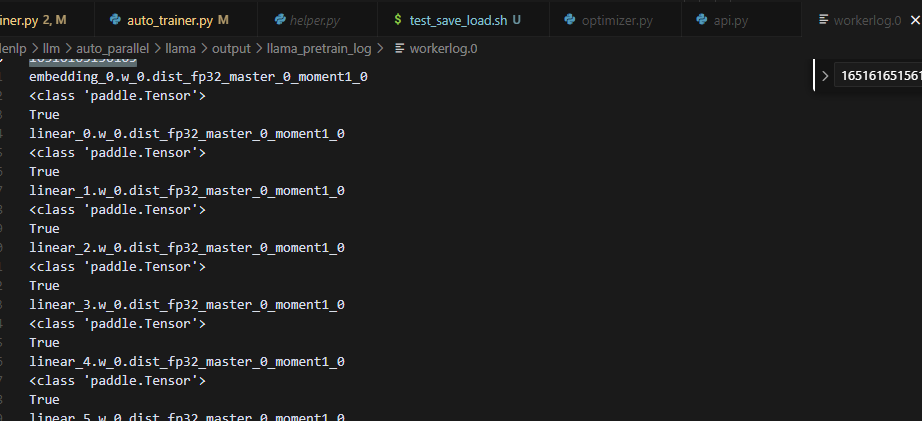
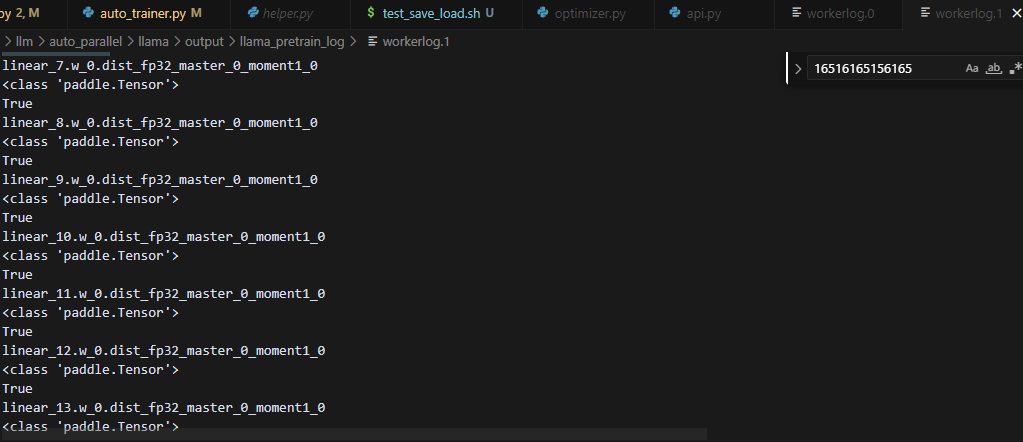
在forward_backward过程中,动态创建了Optimizer的参数,并且没有重命名,而是全局视角的命名
模型参数也是全局名称: