分布式学习记录总结
1.通信方式
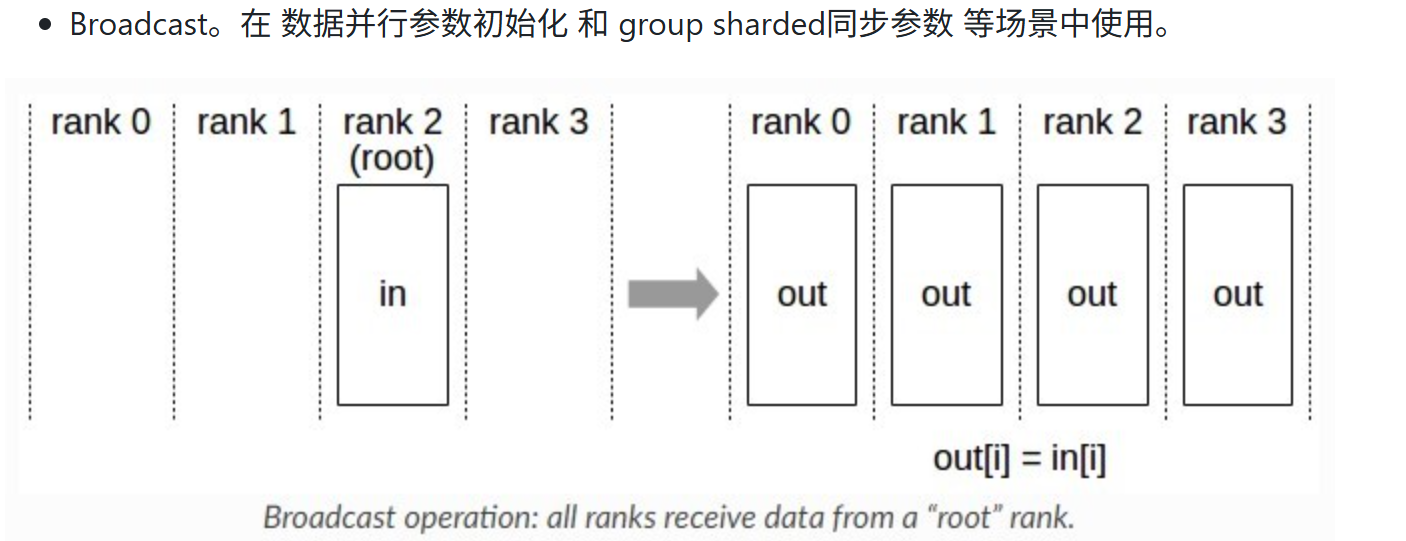
1.1 Broadcast
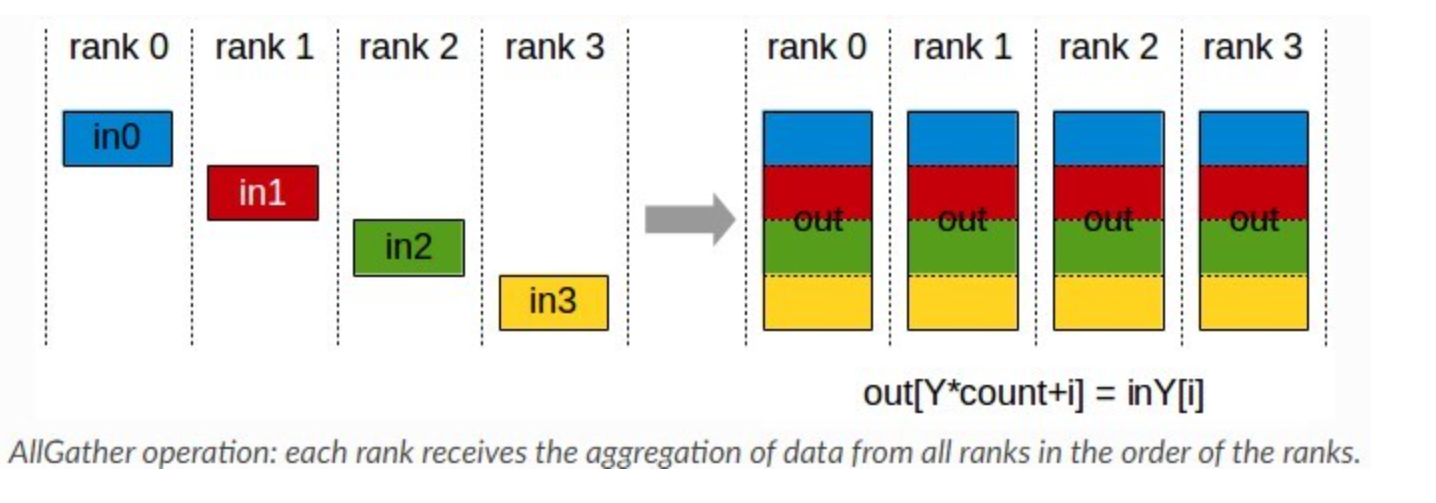
1.2 AllGather
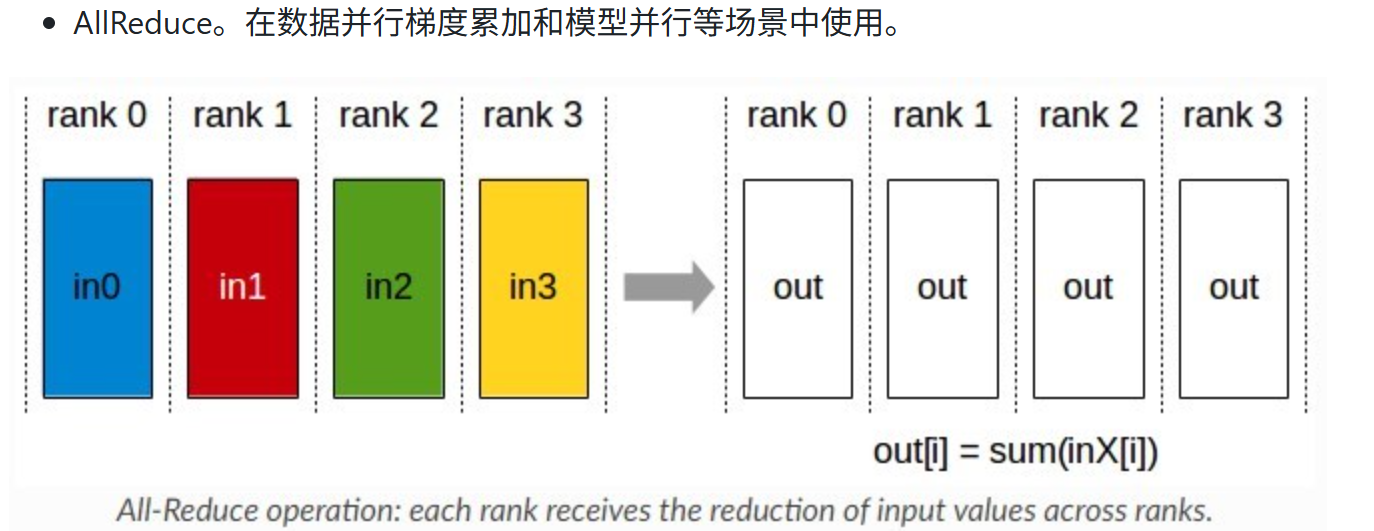
1.3 AllReduce
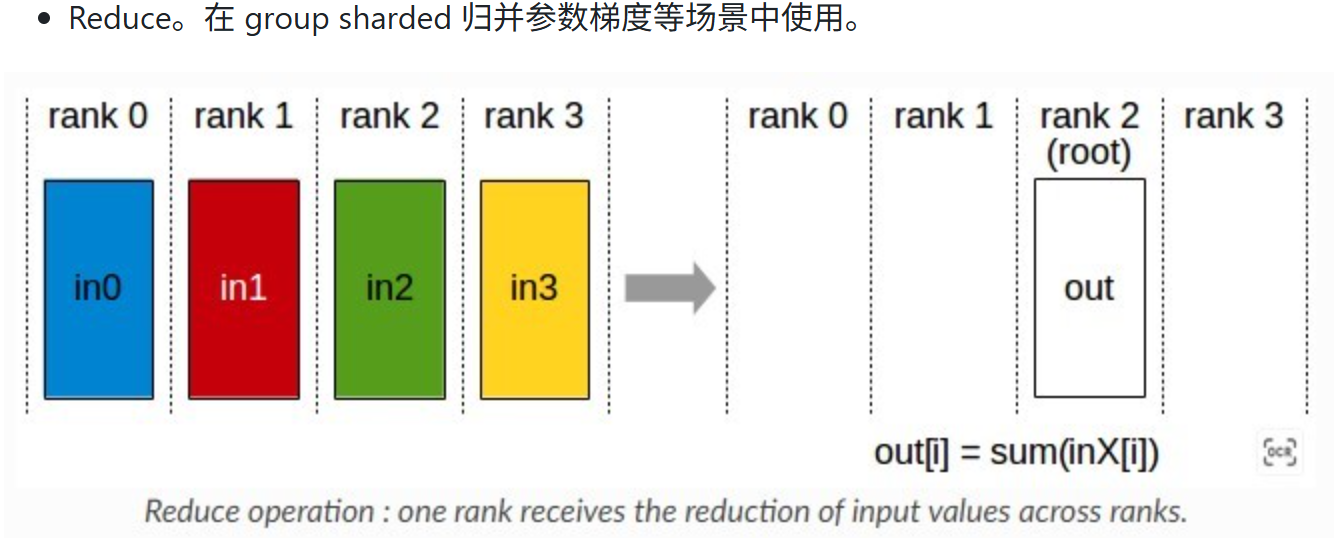
1.4 Reduce
1.5 ReduceScatter
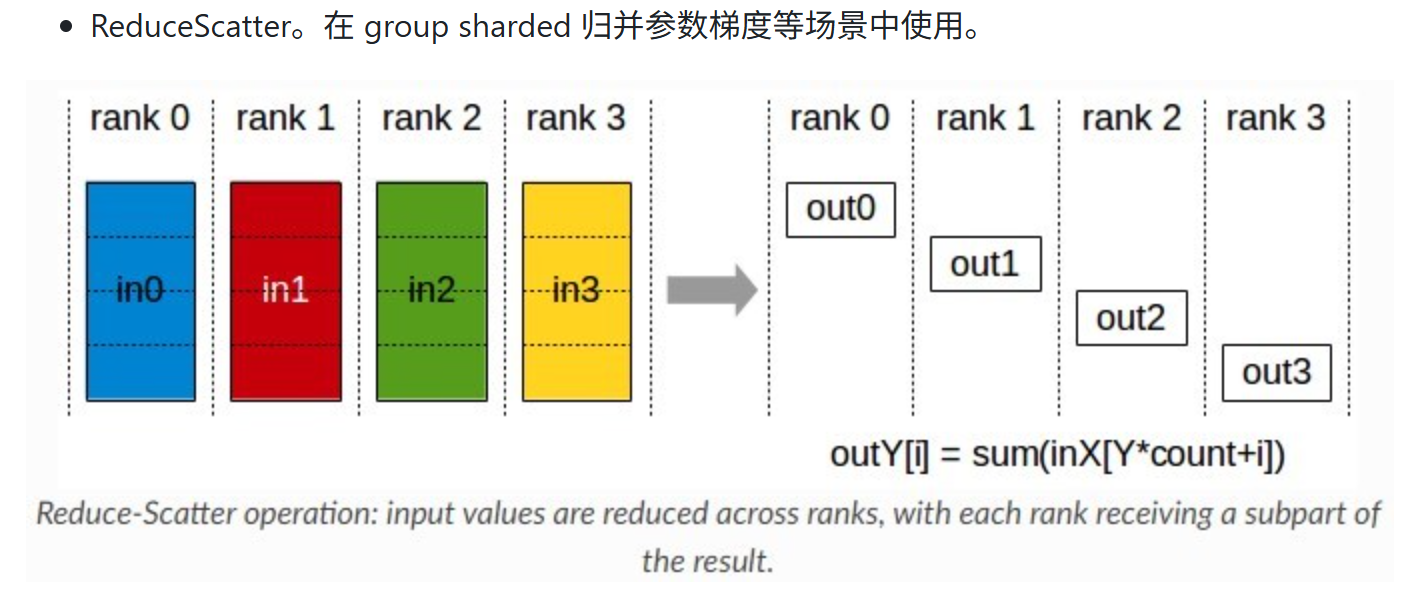
1.6 总结
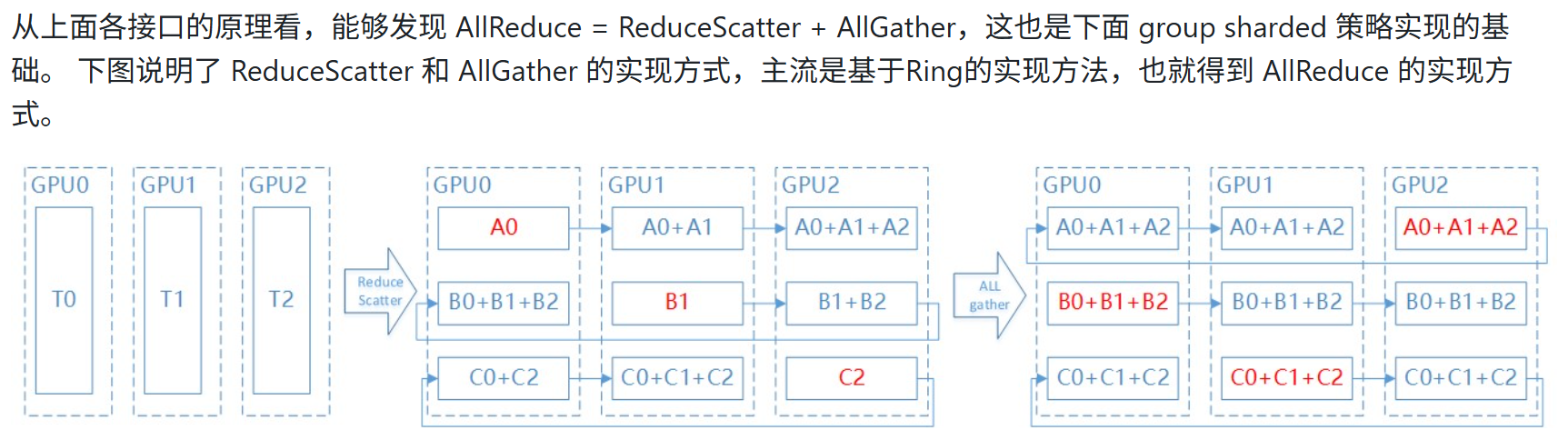
这里怎么理解AllReduce = ReduceScatter + AllGather,主要是因为ReduceScatter 把每张卡的值汇总起来,做reduce(可能是sum,average等),然后把结果分成rank个sub_result部分,分别给每个rank,而AllGather再把这rank个sub_result给聚合起来到每个rank上,则每个rank都有完整的result。其机制就跟直接做allreduce一样,对每个rank的数据汇总做reduce,然后把result分到每个rank上。
2. 三类通信区分动手,动半,静态全自动

同时,在动手的案例中不会出现dist_tensor,shard这些东西,因为这是动半特有的,对通信进行标记使用shard,而tensor被shard处理后,即变成了dist_tensor。
2.1 数据并行
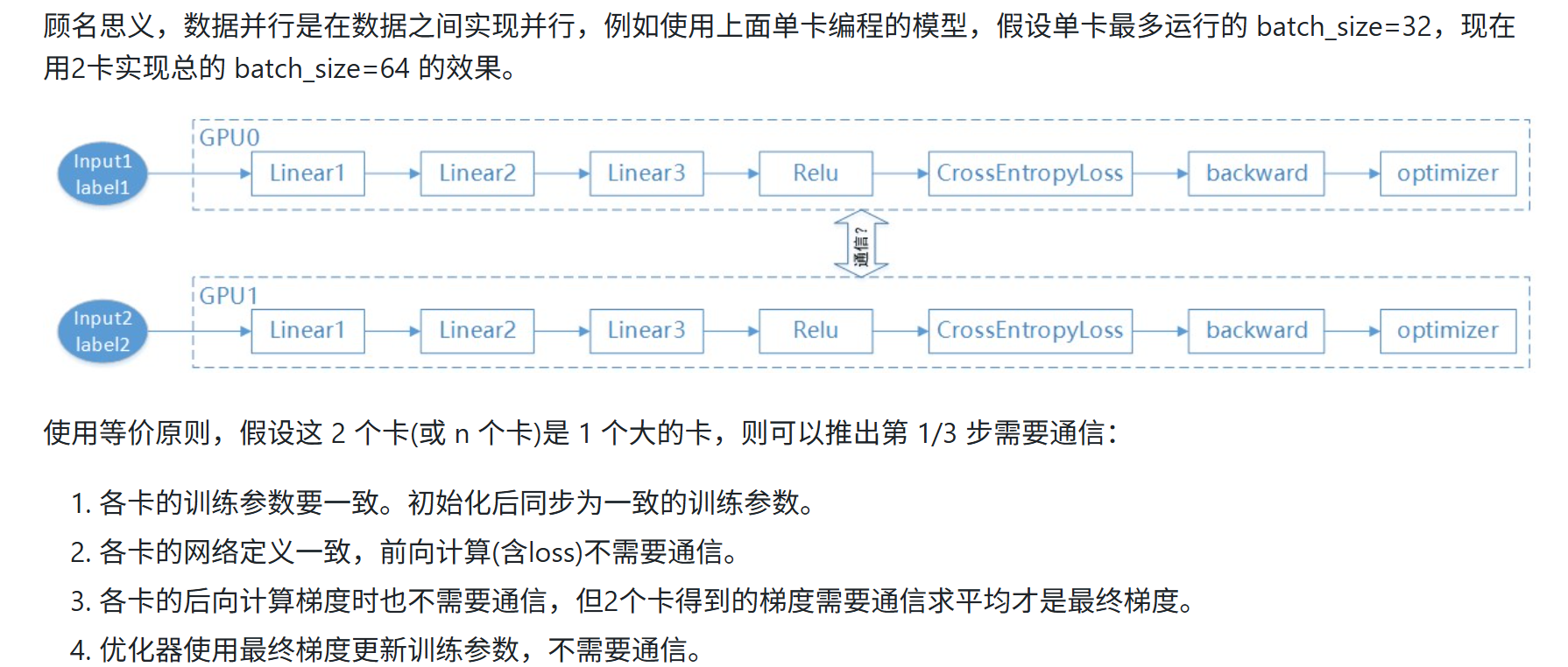
1通信为了让数据并行模型参数保持一致,3通信是为了让梯度累加;在反向过程中,本层的∇x梯度计算完毕后,可以继续计算下一层的∇x梯度,而不需要等待∇w的梯度计算,当对∇x梯度做allreduce通信时,可以做∇w的梯度计算;而做∇x梯度的计算时,又可以做∇w的allreduce通信,从而达到通信与计算重叠。
注意: 数据并行分两种,上面是DDP,即Distribute_DP是基于多进程实现的,还有一种是DP,是单进程多线程实现,如下图所示,它使用一个进程来计算模型权重。
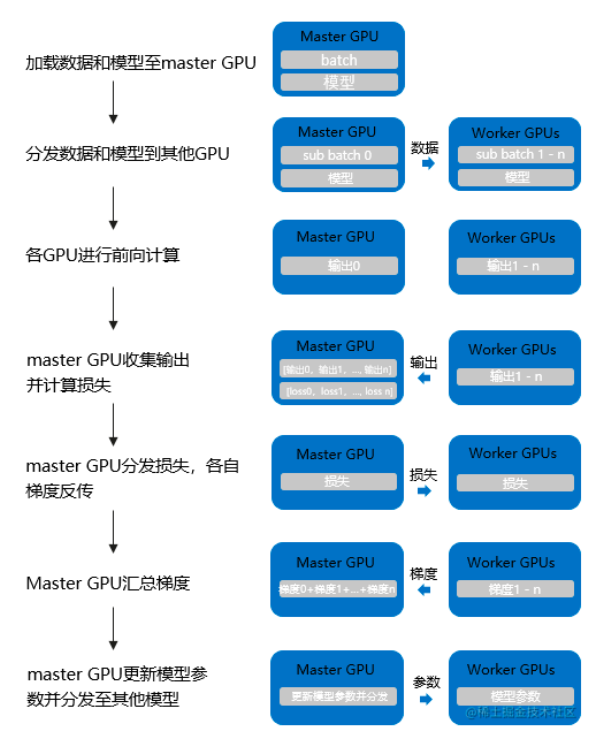
注意: 二者效果是等价的,因为假设我们DP实现batchsize为64的数据量,对于DP来说,它会在计算loss时,汇总64条数据的output,然后和lable计算出loss,并得到一个平均的loss,再传给各GPU进行反向传播,此时每个grad就是平均之后的,即除以了64的。而DDP 则分给两个GPU各自去计算梯度,每个GPU计算的梯度也是mean的,不过是除以32的,所以要再allreduce一下,两个相加除以2,即同样是除以64。
2.2 补充说明:ZeRo(DeepSpeed提出) 以及FSDP(Pytorch最新数据并行方案)

ZeRO-1:
ZeRO-1没有将模型本身进行分片,也没有将Gradient进行分片,而是只将优化器进行分片。训练过程与DDP类似。
- forward过程由每个rank的GPU独自完整的完成,然后进行backward过程。在backward过程中,梯度通过allReduce进行同步。
- Optimizer state 使用贪心策略基于参数量进行分片,以此确保每个rank几乎拥有相同大小的优化器内存。
- 每个rank只负责更新当前优化器分片的部分,由于每个rank只有分片的优化器state,所以当前rank忽略其余的state。
- 在更新过后,通过广播或者allGather的方式确保所有的rank都收到最新更新过后的模型参数。
ZeRO-1 非常适合使用类似Adam进行优化的模型训练,因为Adam拥有额外的参数m(momentum)与v(variance),特别是FP16混合精度训练。ZeRO-1 不适合使用SGD类似的优化器进行模型训练,因为SGD只有较少的参数内存,并且由于需要更新模型参数,导致额外的通讯成本。ZeRO-1只是解决了Optimizer state的冗余。
ZeRO-2:
相比于ZeRO-1,ZeRO-2除了对optimizer state进行切分,还对Gradient进行了切分。
像ZeRO-1一样将optimizer的参数进行分片,并安排在不同的rank上。在backward过程中,gradients被reduce操作到对应的rank上,取代了all-reduce,以此减少了通讯开销。 每个rank独自更新各自负责的参数。在更新操作之后,广播或allGather保证所有的ranks接收到更新后的参数。
ZeRO-3:
为了进一步节省更多的内存,ZeRO-3提出进行模型参数的分片。类似以上两种分片方式,ranks负责模型参数的切片。可以进行参数切片的原因主要有以下两点:
- All-Reduce操作可以被拆分为Reduce与allgather操作的结合。
- 模型的每一层拥有该层的完整参数,并且整个层能够直接被一个GPU装下。所以计算前向的时候,除了当前rank需要的层之外,其余的层的参数可以抛弃。从这个层面上来说,Zero相当于数据并行+模型并行。
FSDP:
FSDP 是一种新型数据并行训练方法,但与传统的数据并行不同,传统的数据并行维护模型参数、梯度和优化器状态的每个 GPU 副本,而 FSDP 将所有这些状态跨数据并行工作线程进行分片,并且可以选择将模型参数分片卸载到 CPU。
下图显示了 FSDP 如何在 2 个数据并行进程中工作流程:
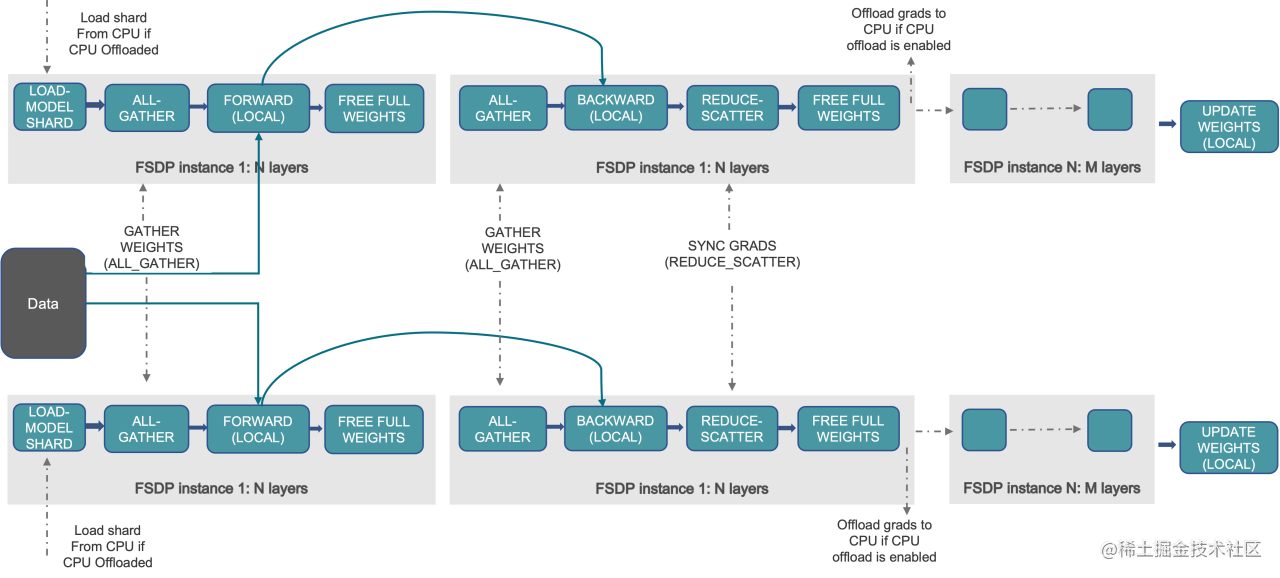
通常,模型层以嵌套方式用 FSDP 包装,因此,只有单个 FSDP 实例中的层需要在前向或后向计算期间将完整参数收集到单个设备。 计算完成后,收集到的完整参数将立即释放,释放的内存可用于下一层的计算。 通过这种方式,可以节省峰值 GPU 内存,从而可以扩展训练以使用更大的模型大小或更大的批量大小。 为了进一步最大化内存效率,当实例在计算中不活动时,FSDP 可以将参数、梯度和优化器状态卸载到 CPU。