Grad_Clip精度对齐
1.动手调用ClipGradByGlobalNorm分析
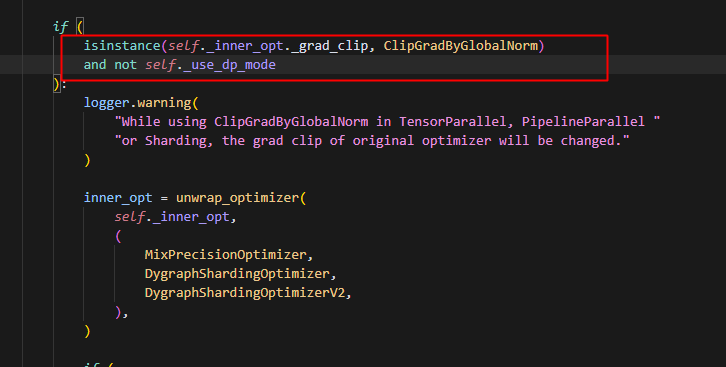
发现纯pp这里会被hybrid_parallel_optimizer自动处理,因此走不到ClipGradByGlobalNorm
![]()

发现如果是dp,则不会出发这个警告,尝试动手下纯dp,发现只有动手只有纯dp会走到ClipGradByGlobalNorm的_dygraph_clip,且其中的src_mesh为None,因为动手是单卡视角,所以process_mesh都是None。
2.动半朴素流水并行下调用ClipGradByGlobalNorm分析
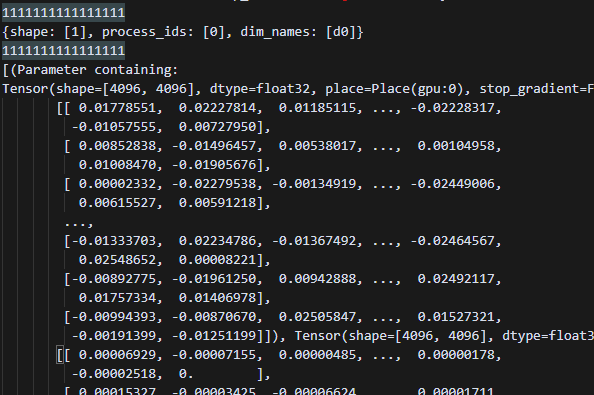
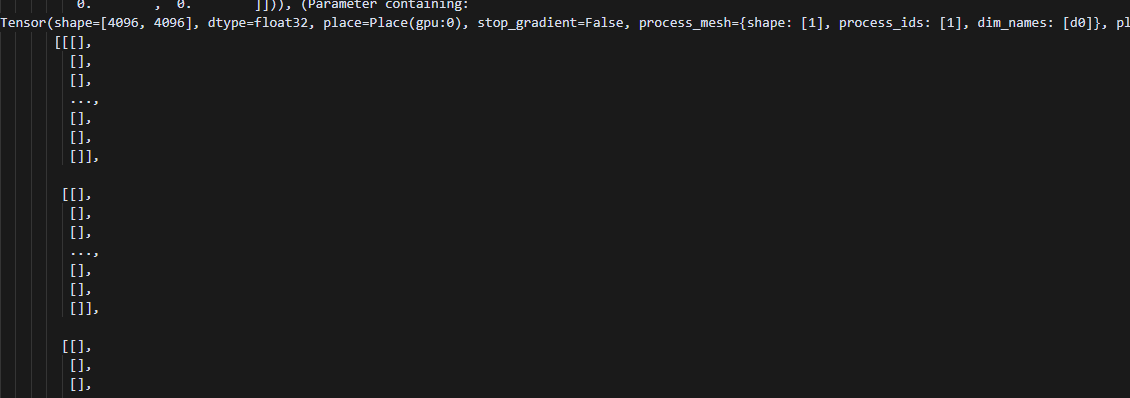
原来的动半pp,会发现保留了其它stage的信息,并且src_mesh均为pp_stage0对应的mesh,因为朴素流水并行使用的shard实现p2p通信,每个stage上都保存了pp_stage0的grad信息,因此每个rank运行到此处时src_mesh = params_grads[0][0].process_mesh均是pp_stage0的grad信息。
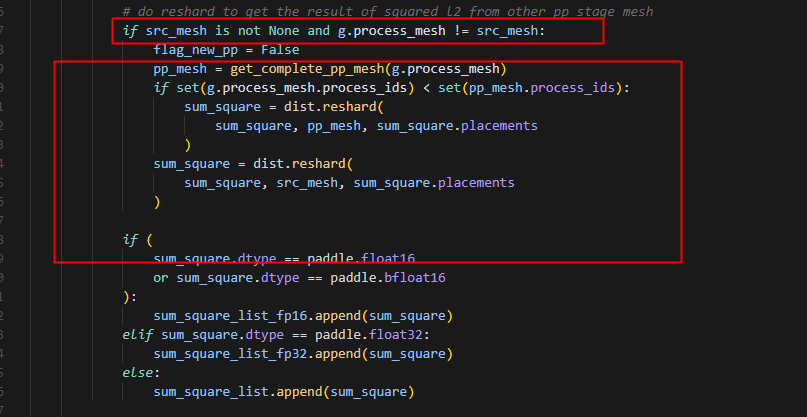
当g.process_mesh != src_mesh的时候,会把所有的sum_square都发送到stage0对应的rank上,最终计算出来的global_norm_var也是在0卡上,并根据global_norm_var计算clip_var,即如果max_global_norm<global_norm_var就用max_global_norm/global_norm_var,否则clip_var就等于max_global_norm/max_global_norm=1,而此时clip_var也是仅分布在stage0对应的rank上,再次遍历grad,当g.process_mesh != clip_var.process_mesh的时候,把clip_var(代码中更新为clip_input)reshard到对应的g.process_mesh,实现不同stage间的pp通信
3.动半新的pp框架下调用ClipGradByGlobalNorm分析
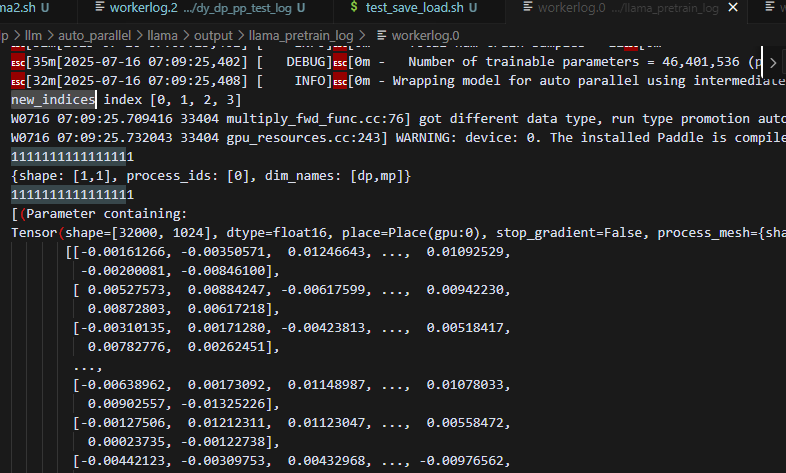
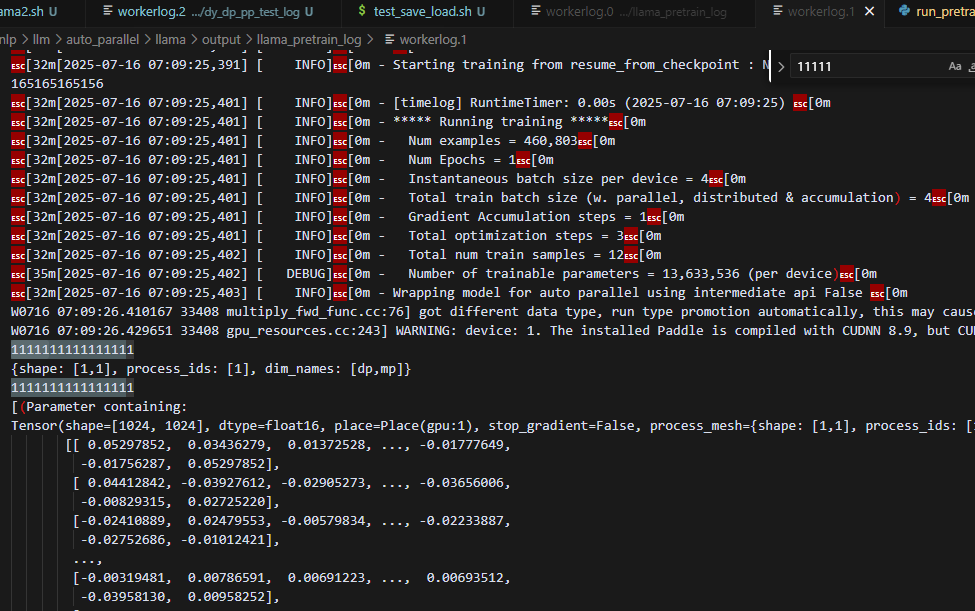
每个pp_stage对应自己的模型参数的信息,只有自己持有的模型参数的梯度信息(所以,所有梯度的process_mesh保持一致,不会有其它stage的梯度信息),因此不会出现grad的process_mesh != src_mesh的情况。所以可以根据此来区分以前的动半pp(例如朴素流水并行),和现在的pp的执行逻辑。
4.模式对齐
和动手对齐:
if (
flag_auto_hybrid_pp and src_mesh is not None and is_pp_enable
): # Use new pp_flask,At this point global_norm_var it's sub_norm_var_sum,we need to sum it between different pp_stage
global_pp_mesh = global_mesh.get_mesh_with_dim("pp")
reorder_mesh = global_pp_mesh._mesh.reshape(
global_mesh.get_dim_size("pp"), -1
)
curr_rank = dist.get_rank()
assert curr_rank in global_pp_mesh.process_ids, "current rank is not in pp process mesh"
curr_rank_sub_group = None
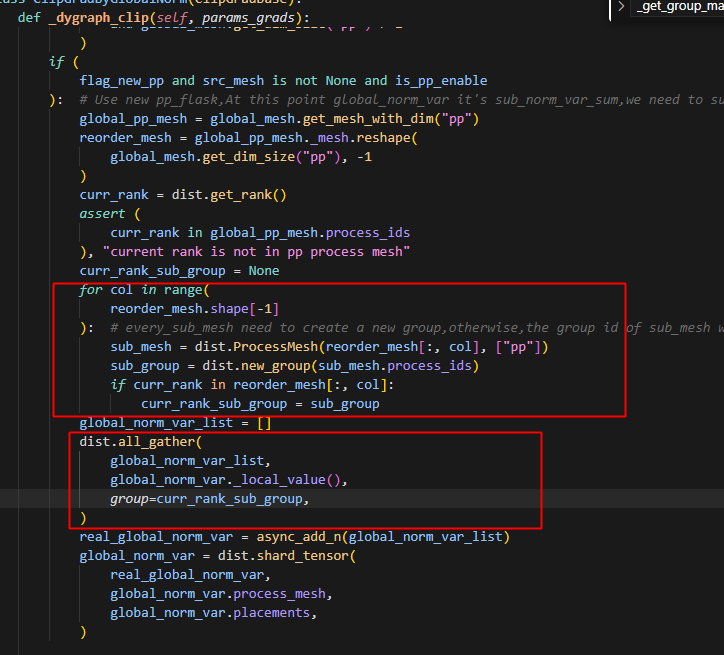
for col in range(reorder_mesh.shape[-1]):#every_sub_mesh need to create a new group,otherwise,the group id of sub_mesh will be the same,which will cause the all_gather error
sub_mesh = dist.ProcessMesh(reorder_mesh[:, col], ["pp"])
sub_group = dist.new_group(sub_mesh.process_ids)
if curr_rank in reorder_mesh[:, col]:
curr_rank_sub_group = sub_group
global_norm_var_list = []
dist.all_gather(global_norm_var_list, global_norm_var._local_value(), group=curr_rank_sub_group)
real_global_norm_var=async_add_n(global_norm_var_list)
global_norm_var=dist.shard_tensor(real_global_norm_var,global_norm_var.process_mesh,global_norm_var.placements)
因为动手也是单卡视角,每个卡分别计算对应的global_norm_var(所有梯度平方相加),得到一个子sub_global_norm_var,然后再相加得到全局的global_norm_var,因此我们首先得到pp为最外维度的processmesh,紧接着将其展开成二维张量,pp在第一个维度,此时建立通信组,即不同pp_stage的每个rank分别建立一个group,即reorder_mesh的每一列即为一个通信组,只用包含本rank的通信组(其它不用的group也要建立,不然会报错,因为其它rank会用到,其它rank就会建立,而本rank也要有同样的创建操作),使用all_gather在这个通信组之间进行通信,得到所有的global_norm_var,再全部相加得到global_norm_var,相加后,再shard global_norm_var到对应的process_mesh即可(这一步其实是为了将real_global_norm_var此时是一个dense_tensor转换成dist_tensor)。
和动半对齐*(当前问题是在哪里加param.grad的初始化,因为step是在每个优化器继承Optimizer之后又重载实现的,所以step都是独立的,要加的话,可能要在每个优化器的step里面加,现在的通用方法就是在Optimizer加一个方法,然后在所有optimizer的step中调用此方法(或者加装饰器)):
目前的想法是,像朴素流水并行的动半一样,给每个stage都加上其它stage上的参数和梯度信息(未初始化的),即在optimizer.step的时候,对于param._grad_ivar() is None的参数,创建梯度信息(因为pp只会用到自己对应的那部分参数,所以只是梯度信息(未初始化)并不影响其它计算),此处展示了一个在Adamw中的step方法中加上梯度初始化的结果和当前默认以动手的逻辑处理的结果的对比。
1. 在step的时候对其它非本stage的梯度初始化后的global_norm_var的结果:

2. 默认动手逻辑的结果:



对齐方法如下:
给Optimizer.step方法添加装饰器(可以放别的地方,但目前不知道放哪里比较好)
def in_auto_parallel_align_mode_handle_none_gradients_in_step(step_method):
def wrapper(self, *args, **kwargs):
import paddle.distributed as dist
if dist.in_auto_parallel_align_mode():
for param in self._parameter_list:
if param.stop_gradient:
continue
if param._grad_ivar() is None:
param.grad = paddle.zeros_like(param, dtype=param.dtype)
return step_method(self, *args, **kwargs)
return wrapper
在实际使用时,动态地给step方法添加此装饰器(因为主要是为了对齐精度使用,给每个优化器的step都添加此方法,破坏代码结构,并且有些冗余,不是必要的,因此只在使用时,封装即可)

5.在auto_trainer中添加装饰器
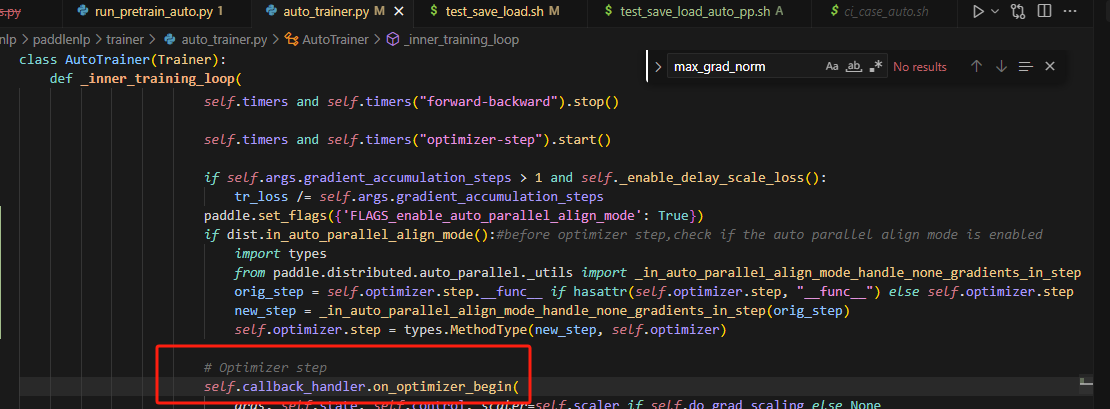
在optimizer.step开始前,对梯度为None的参数初始化梯度参数即可。
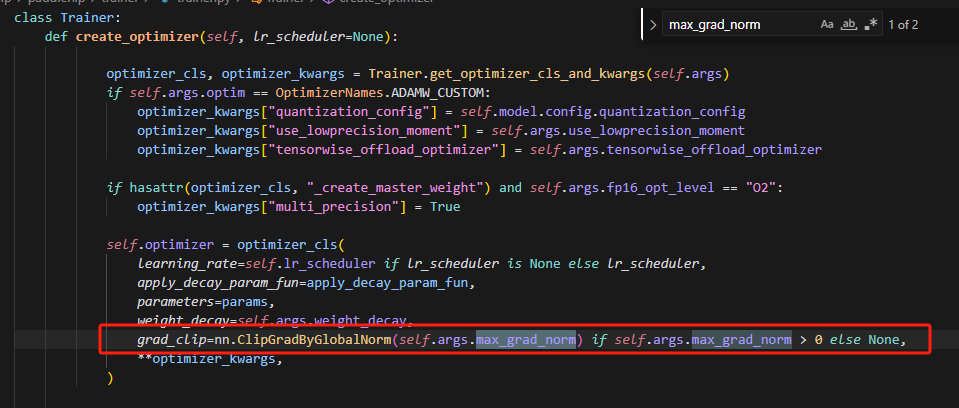
grad_clip在trainer.py中定义,并且传递max_grad_norm参数。
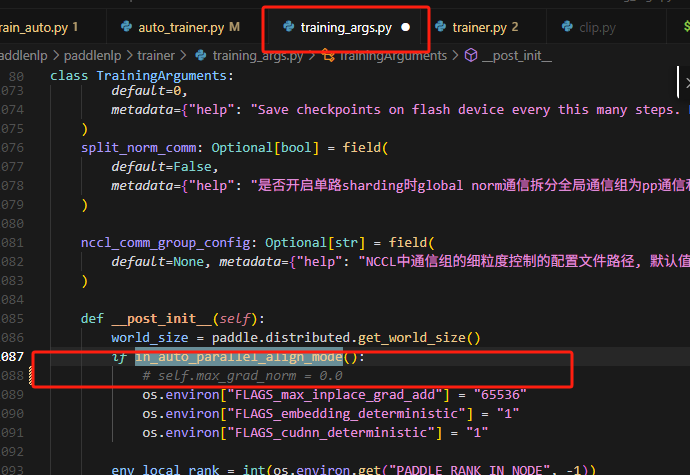
当前align_mode的max_grad_norm被设置成了0.0
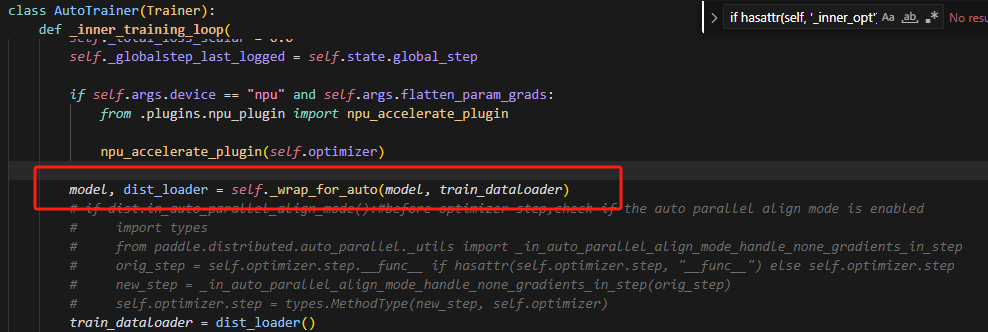
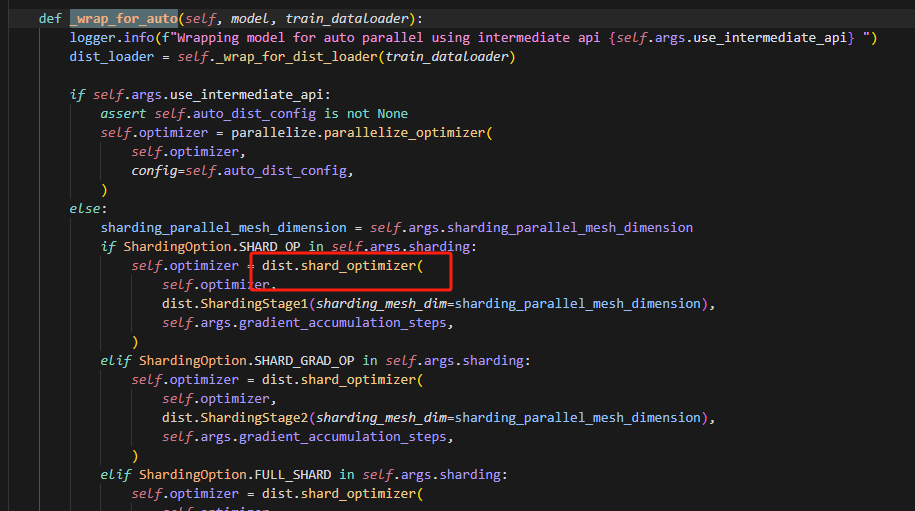
在auto_trainer中加装饰器出错(没有触发装饰器),原因是,shard_optimizer包裹了原来的初始optimizer(默认是Adamw),使用装饰器,包裹optimizer.step后,此时包裹的是Adamw.step方法,然而,发现在api中如下:
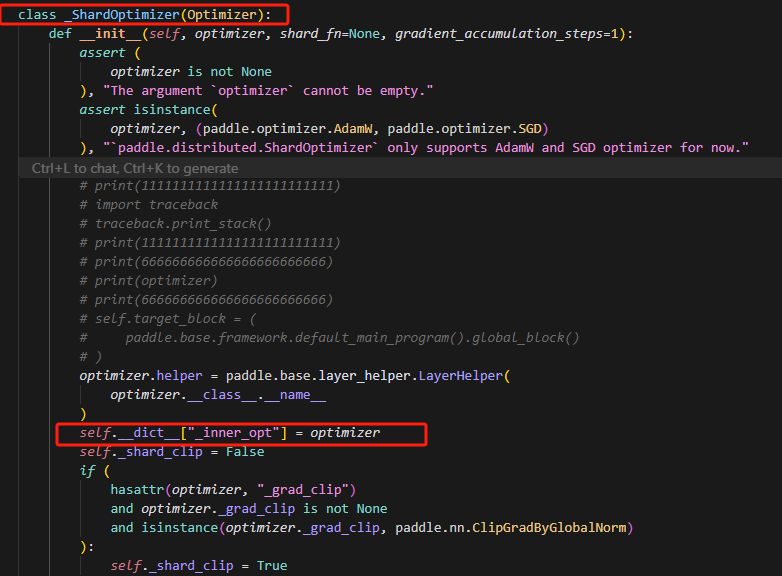
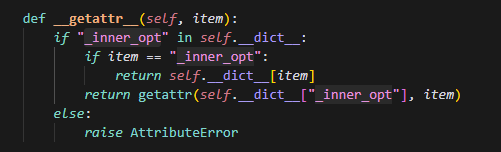
设置了属性inner_opt为传入的optimizer,这个optimizer即前面提到的默认的Adamw,然后可以发现_ShardOptimizer是没有重写step方法的,所以在调用的时候首先会查看是否有该方法,_ShardOptimizer没有,则会在它的父类中找,最后才会查看inner_opt,因此实际调用的是它父类的step方法。
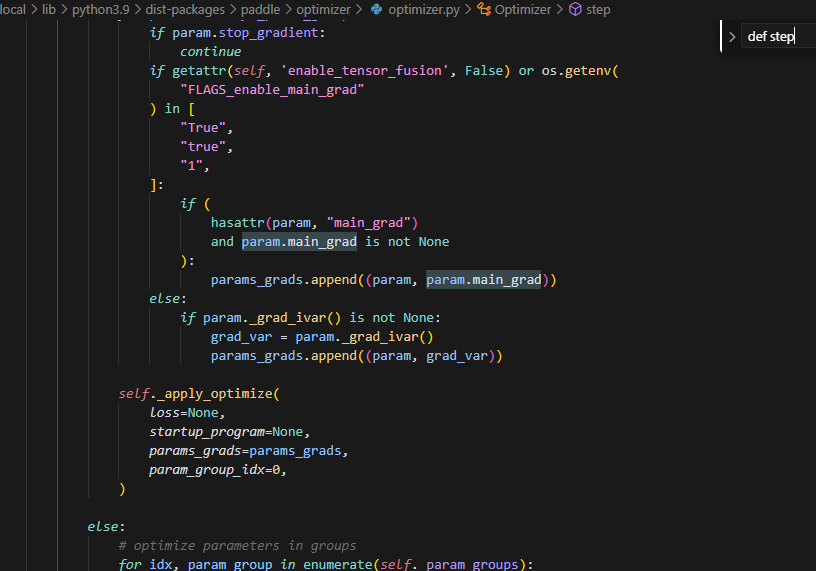
在optimizer的step方法中,会处理params_grads列表,在此处,为None的数据会被过滤掉,所以必须在调用step方法前,做grad初始化。
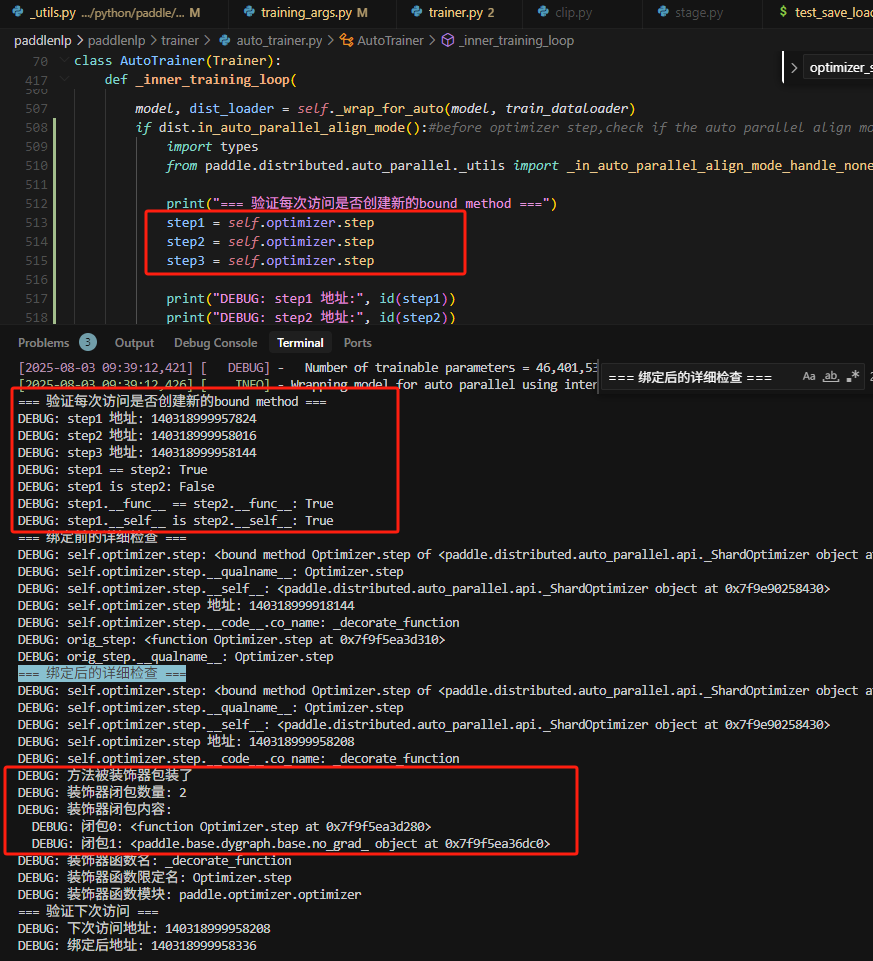
但是发现我们的封装器一直没有加入实际的step方法上,而是加入到了Adawm上面,为什么呢?
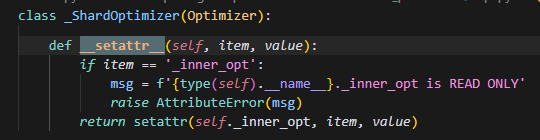


原因在这里,之前直接用.step的方法,会导致将封装的step方法,赋值给_ShardOptimizer的step方法时,触发了setattr方法,导致,把new_step方法即value,赋值给了self._inner_opt这个optimizer实例的step方法,即item,而实际调用时,调用的是ShardOptimizer的父类,即基类Opitimizer的step方法,导致装饰器并没有成功运行。
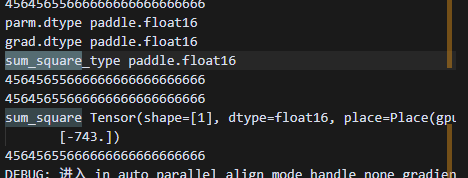
0 卡接收

1 卡发送
修改后,clip中第一次reshard数据出问题,随机初始化,原因是,1卡发送的是float32的数据,而0卡此时的数据信息是float16的精度,就会导致初次接收数据失败,随机初始化。
为什么原来动半pp可以,新的动半pp框架会遇到这个问题
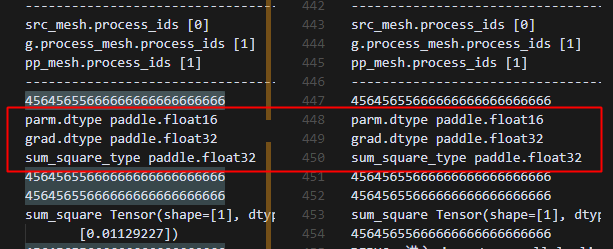
原动半pp结果,1卡给0卡发送数据
跑了一下实验进行对比,可以看到,0卡和1卡的数据类型保持一致的。
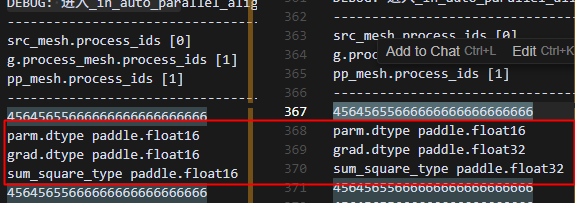
新动半pp结果,1卡给0卡发送数据
此时0卡数据类型和1卡不一致,0卡数据类型是在opt.step之前做的初始化,是和parm类型对齐的,可能因为在哪里做了grad的类型转换,还需要探究。
找到原因
1.原因分析
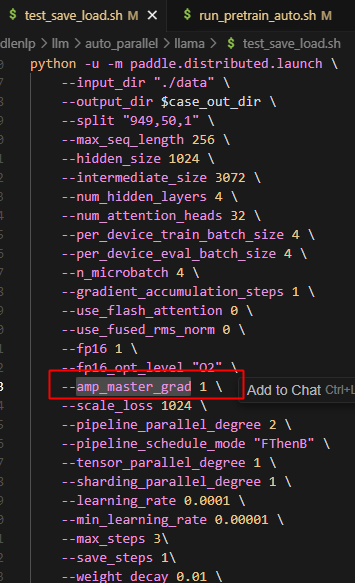
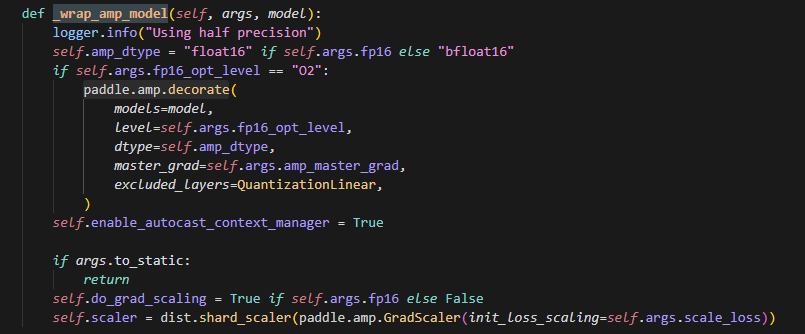
amp_master_grad为true的时候,且此时是半精度,并且opt_level为"02"时,会使用master_grad的逻辑,具体分析如下:
2.master_grad的影响
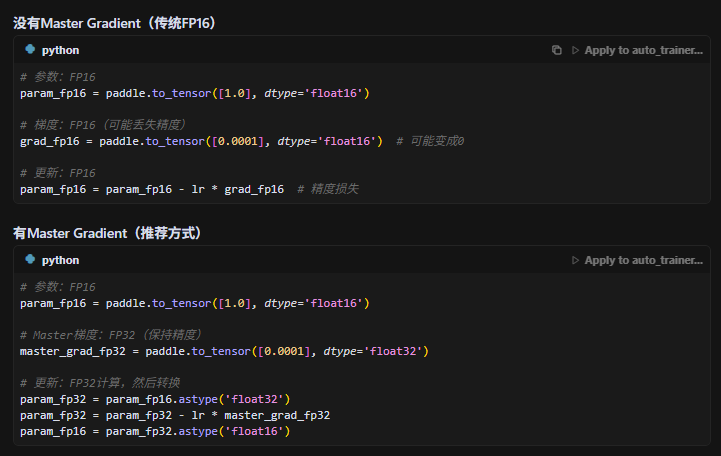
首先master_grad的作用如下,在梯度更新的时候,如果不用更高精度数据做计算,可能造成精度损失:
3.paddle.amp.decorate具体实现逻辑(paddle.amp.auto_cast.py的1179行)
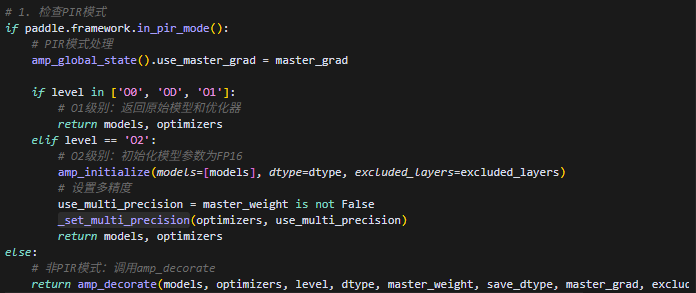
分为PIR模式和IR模式,后面应该基本都对齐PIR模式,两者效果应该是一样的(注意当前只在静态模式下支持pir),以下是amp_decorate的处理
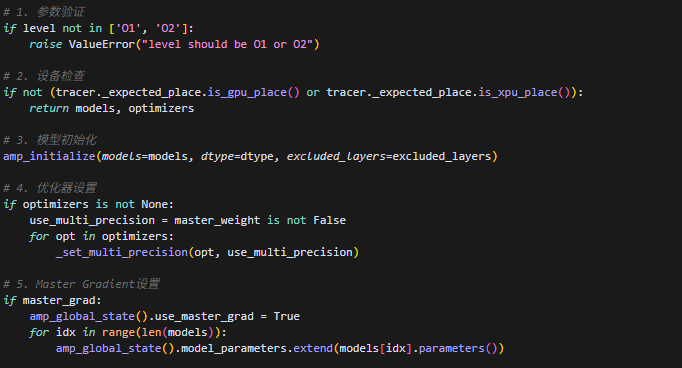
这里dtype是根据训练时设置的精度来初始化模型的,设置的是fp16,这里模型参数初始化就是fp16
4.Master Gradient的具体实现
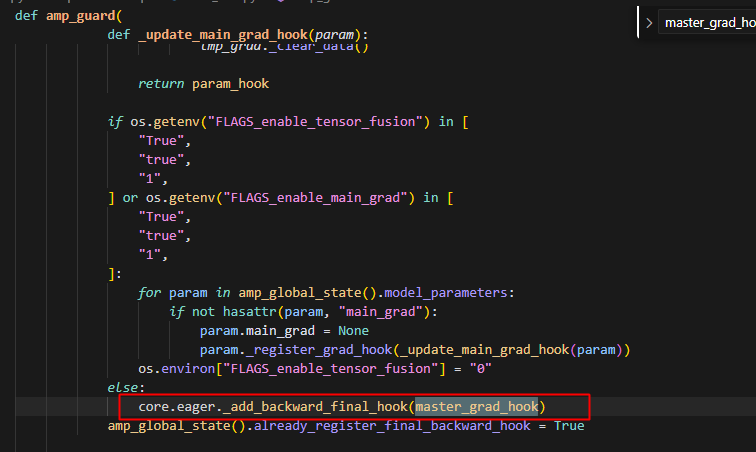
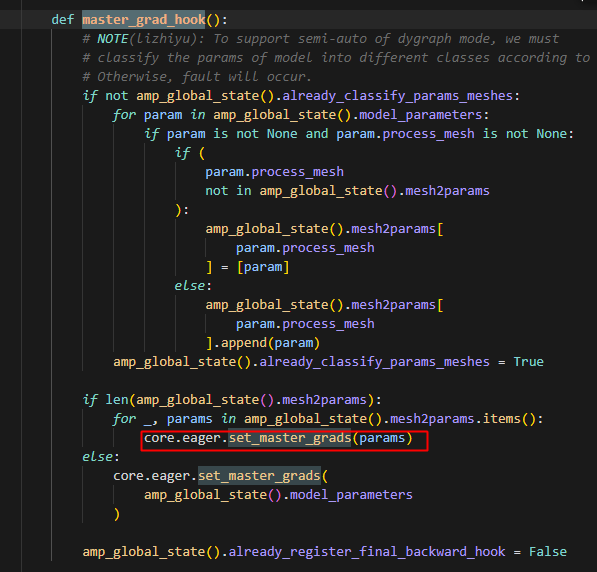
此时走的是master_grad_hook,此处会根据不同的processmesh批量处理对应mesh上的params的grad,以下是set_master_grads逻辑:
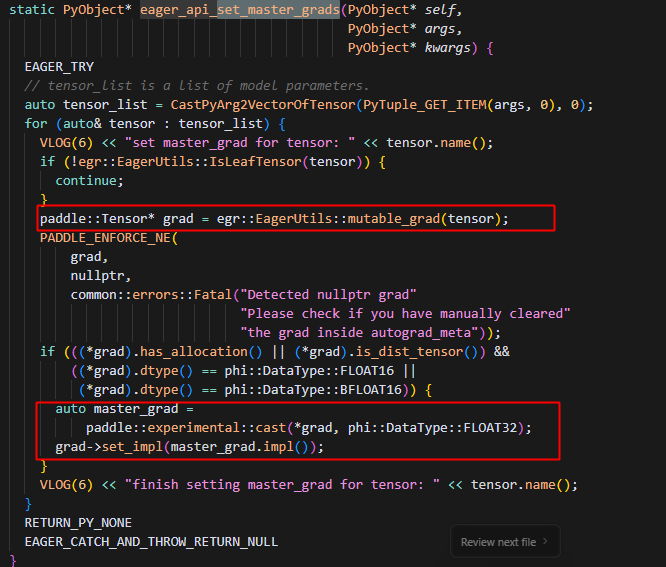
对于分配了内存的grad,会将其转化成float32的精度,这里grad指针指向的是param自身的grad,如下路径证明:
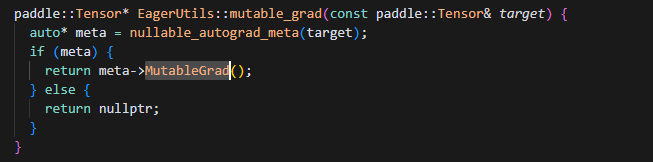
![]()
6.装饰器概念
装饰器的基本概念
函数作为参数: 装饰器就是接收一个函数并返回一个新函数的函数。装饰器接受一个可调用对象(如函数或方法),并且通常在返回的新函数中增强原始函数的功能。
增强功能: 装饰器通常用于增强现有函数的功能,而不需要修改原函数的源代码。这使得装饰器非常适合应用于日志记录、权限检查、性能计时等方面。
语法糖(@符号): Python 为装饰器提供了简洁的语法(
@decorator),使得装饰器的使用变得更加直观。def my_decorator(func):
def wrapper():
print("Something is happening before the function.")
func()
print("Something is happening after the function.")
return wrapper
# 应用装饰器
@my_decorator
def say_hello():
print("Hello!")
say_hello() 由于装饰器通常会改变原始函数的行为,
wrapper函数的签名通常需要和原函数一致。为了避免修改函数签名,可以使用functools.wraps来保持原函数的元数据(如名称、文档字符串等)。
7.main_grad和grad区别与概念
8.grad_clip 动手逻辑优化
当前训练时间:
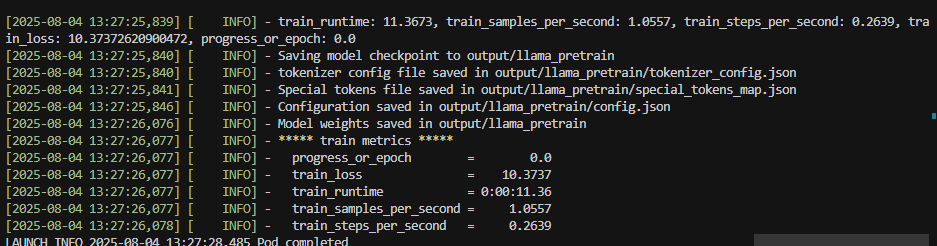
1. 优化all_gather+sum为all_reduce:

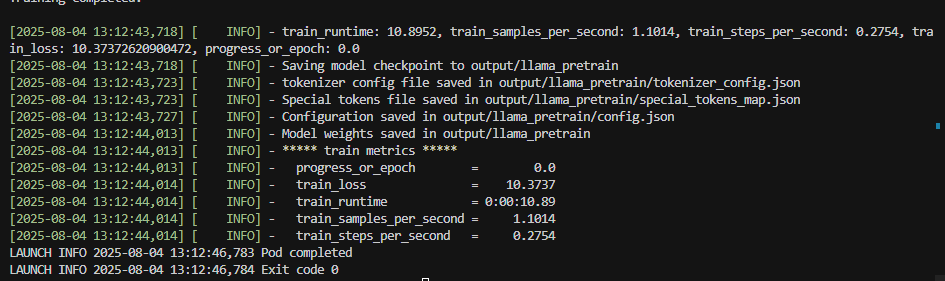
2.优化new_group为get_group,不重复创建通信组
