动半,动手,加local_map的动手日志分析
1.对比local_map下的动半和非local_map的动半(左是非local_map动半(纯动半),右是local_map动半)
1.在进入loss函数计算之前,local_map下的动半和纯动半操作完全相同。
2.进入loss函数计算前,前面会多dtensor_to_local,动半是用dist_tensor在做loss计算,会自动推导进行shard,而local_map动半是使用dtensor_to_local,将其转化为dense_tensor去做
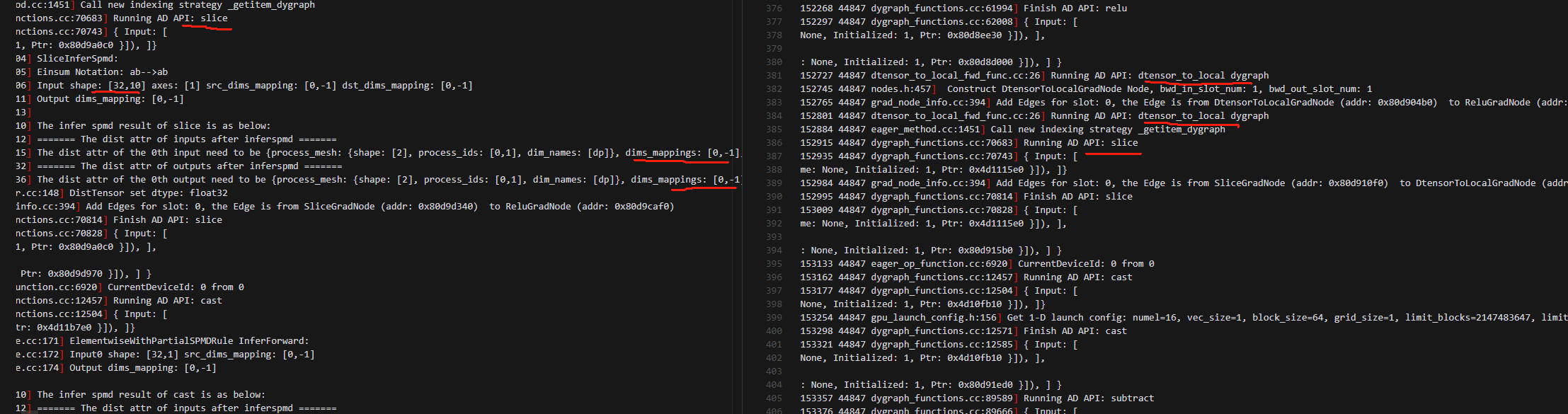
3.做loss函数中的绝对值计算的时候,动半看起来做了allgather?从shard分布,变成了replicated分布
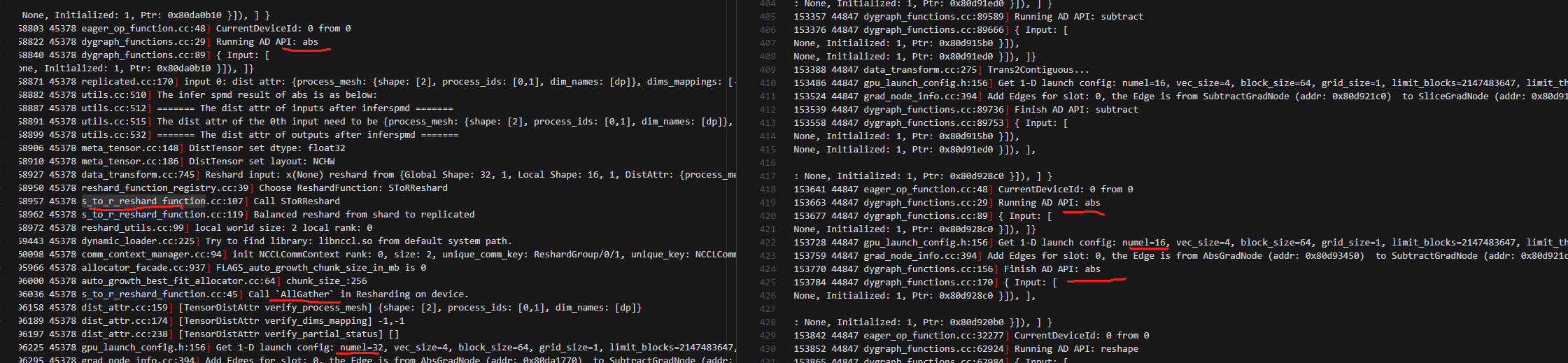
4.绝对值计算后,后面的所有操作,动手用的是[32,1]的数据做的,且dims_mappings:[-1,-1]说明是全复制状态
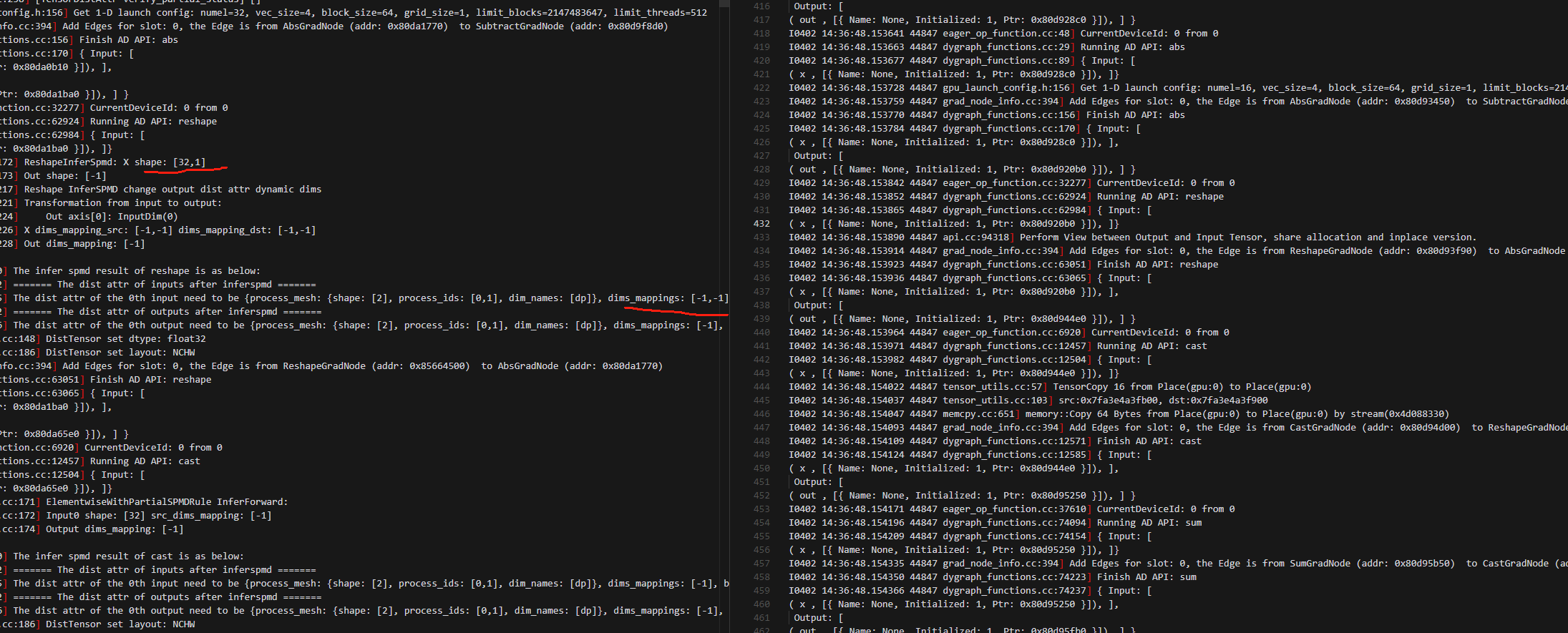
5.进入backward前,使用local_map的动手要多一个dtensor_from_local dygraph
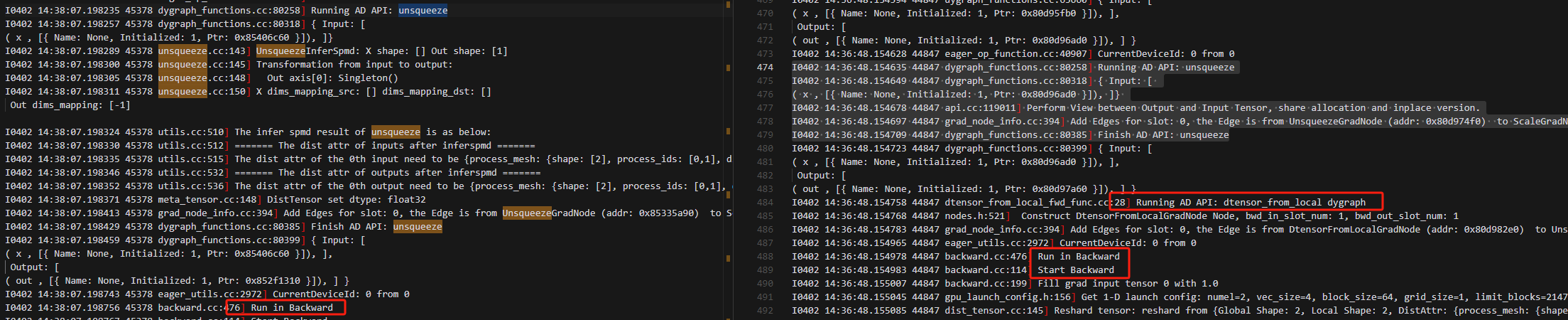
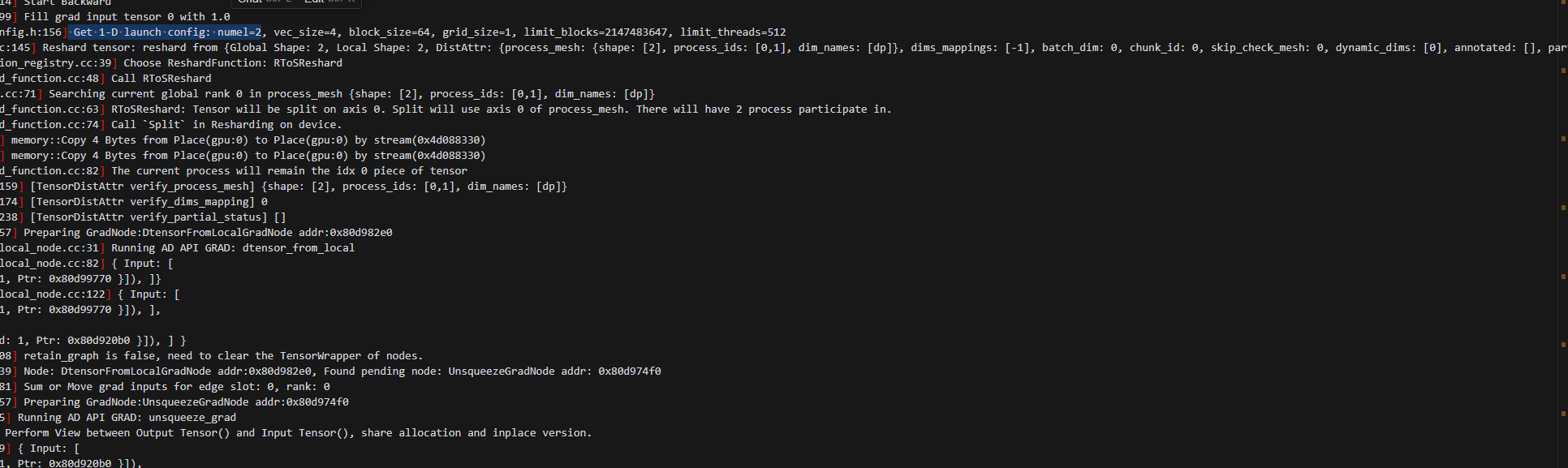
6.开始执行backward时,使用使用local_map的动手需要执行GRAD: dtensor_from_local,在此时Get 1-D launch config: numel=2,然后做了RToSReshard,再做GRAD: dtensor_from_local,紧接着再做GRAD: unsqueeze_grad,此时unsqueeze_grad的输入是GRAD: dtensor_from_local的输出;而纯粹的动手和动半是直接开始做GRAD: unsqueeze_grad,并且输出就是
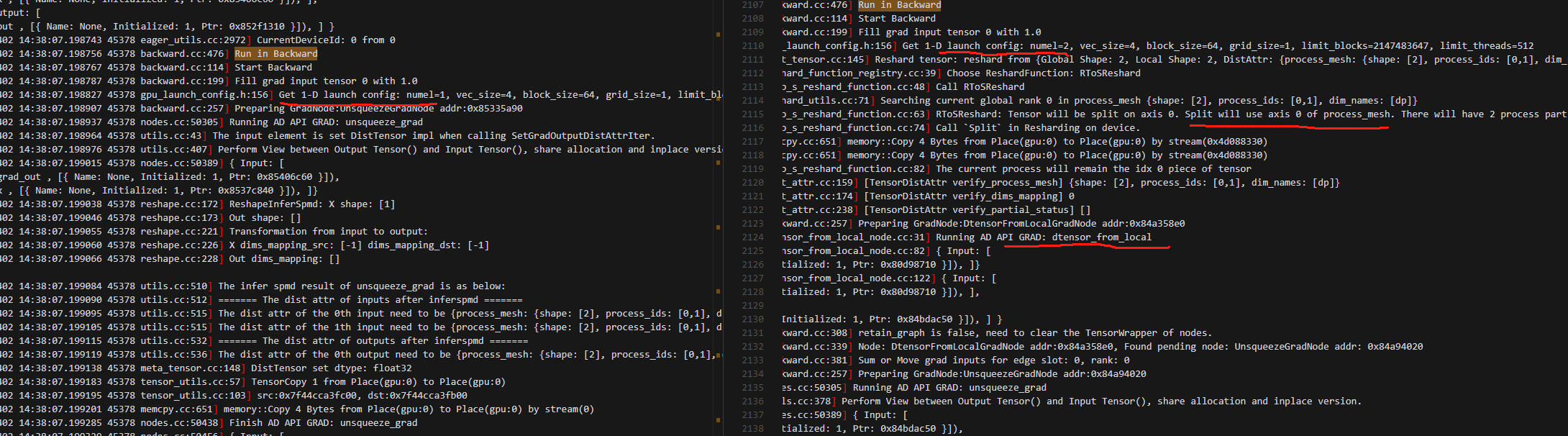
7.反向的时候,local_map包装的loss计算这部分,也动半不同,但和动手相同,这一点从逻辑上看是没问题的。动手会用自动框架的切分推导逻辑,而local_map的动手,则完全是本地视角做backward。
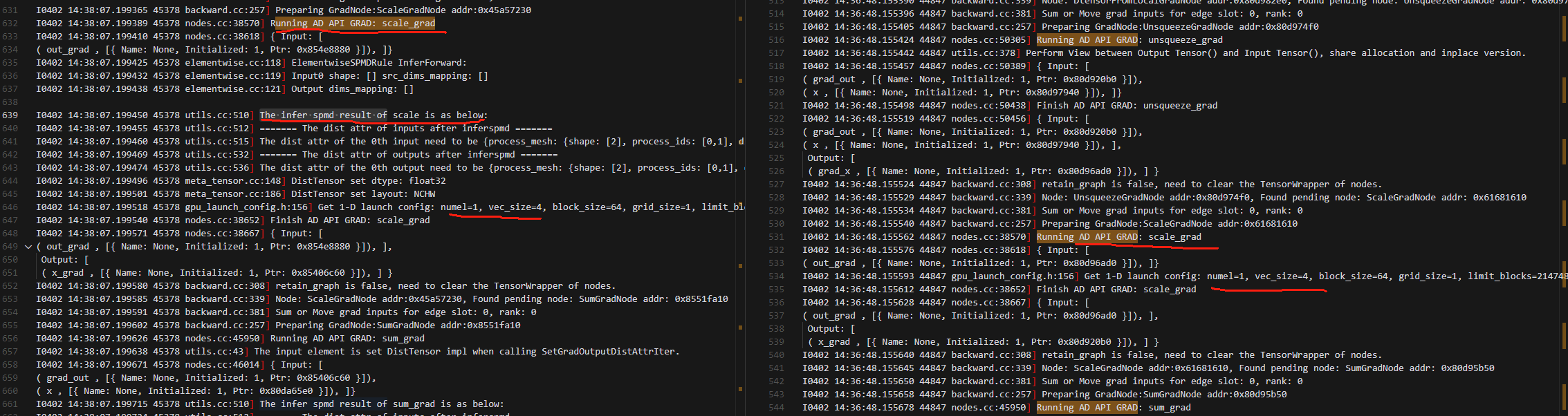
8.local_map的动半 会多出一个Running AD API GRAD: dtensor_to_local;接下来的Running AD API GRAD: relu_grad其中一个输入grad_out,是GRAD: dtensor_to_local输出的结果;而纯动半和动手Running AD API GRAD: relu_grad其中一个输入grad_out,直接由slice_grad得到。
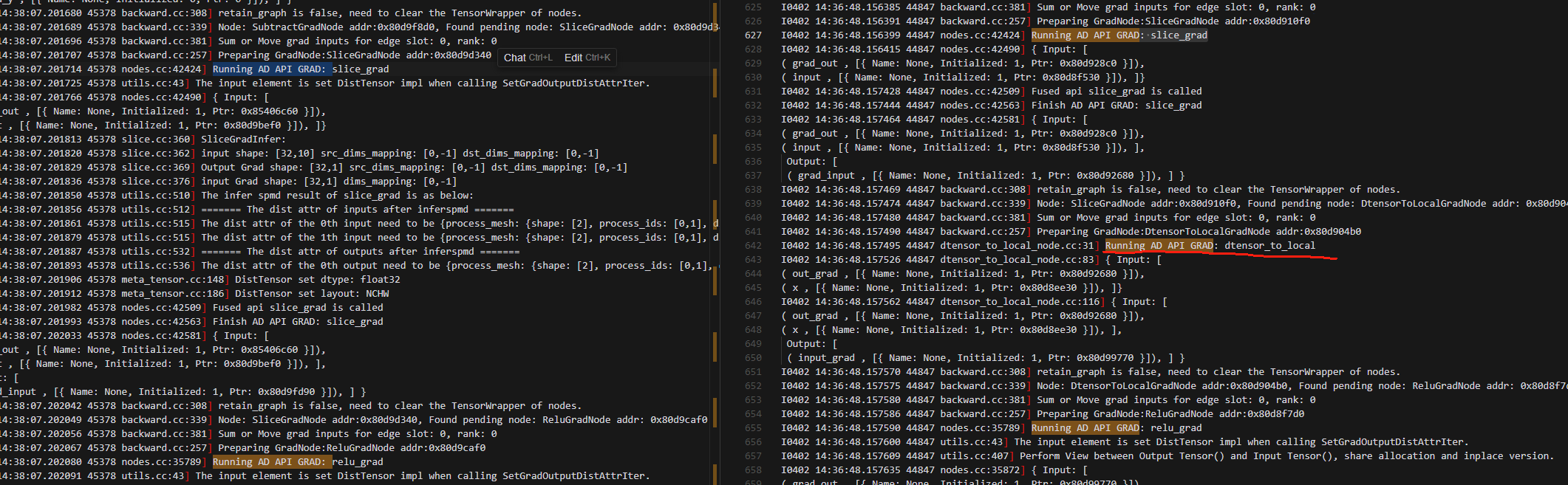
9.后续过程local_map的动半与纯动半完全相同
2.对比动手和local_map下的动半(左是动手,右是local_map动半)
1.不知道反向时这个sum or move grad inputs for edge 是否做了梯度累加?此处多一个dtensor_from_local的梯度计算
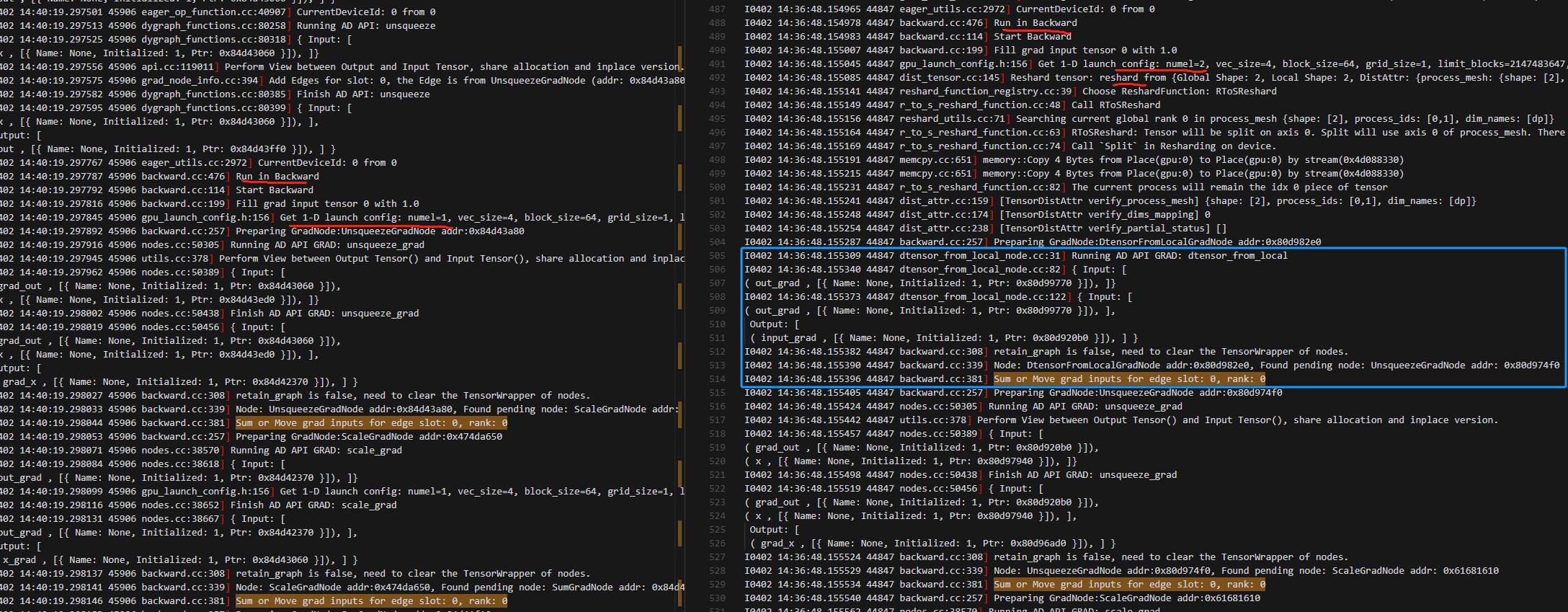
2..反向计算最开始:二者数据大小有差异
第一个是动手的截图
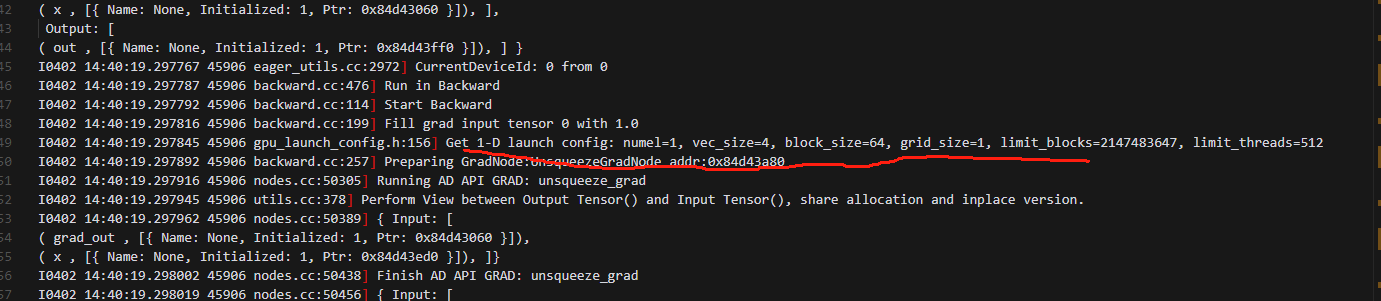
第二个是local_map下的动半的截图
3.进入relu_grad之前,local_map下的动半比动手多一个dtensor_to_local梯度计算
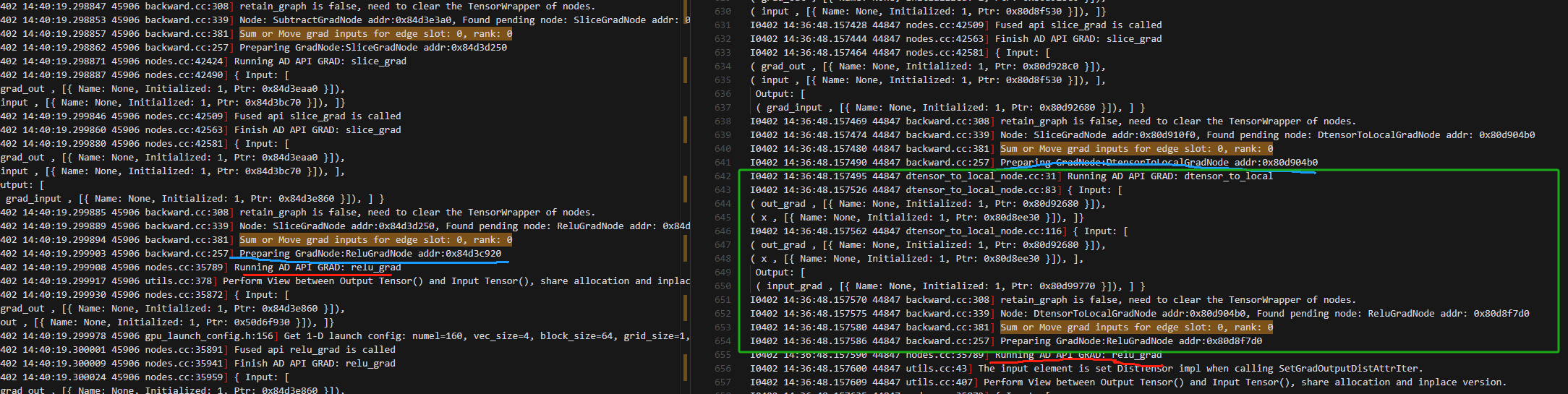
以下都是反向的时候,loss包含的所有操作的grad计算完后的操作,动半(不用local_map)和local_map下的动半是完全相同的,因此和动半有区别我认为属于正常现象
4.做add_grad的时候输出变量维度不同(但是动半(不用local_map)和local_map下的动半操作相同)
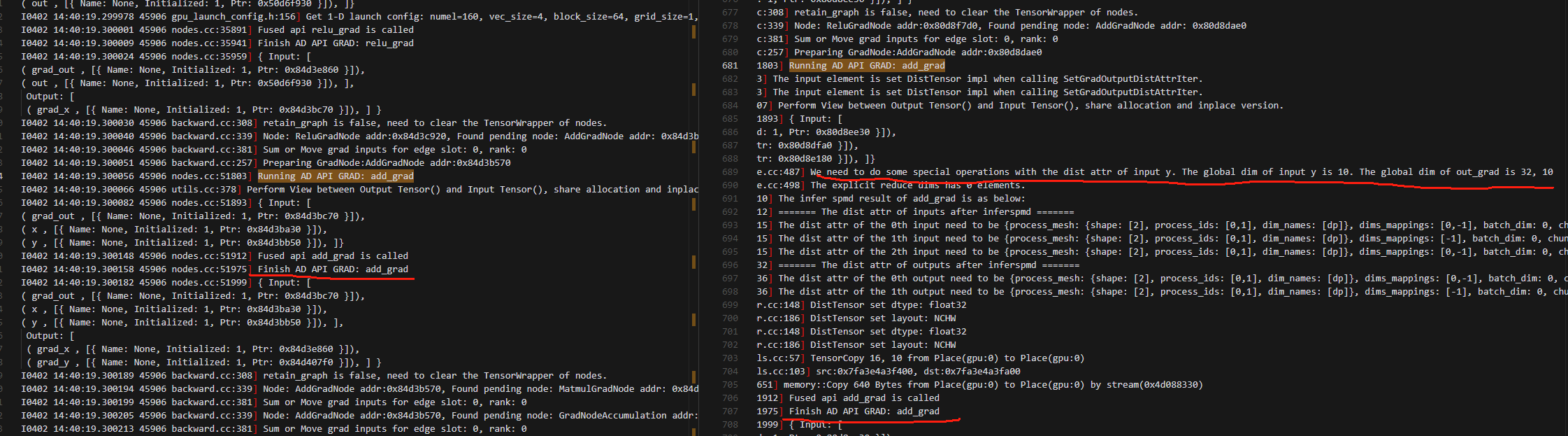
5.动手多一个对偏置b的操作(还有很多这种)

6.matmul_grad 二者有差异(但是动半(不用local_map)和local_map下的动半操作相同)
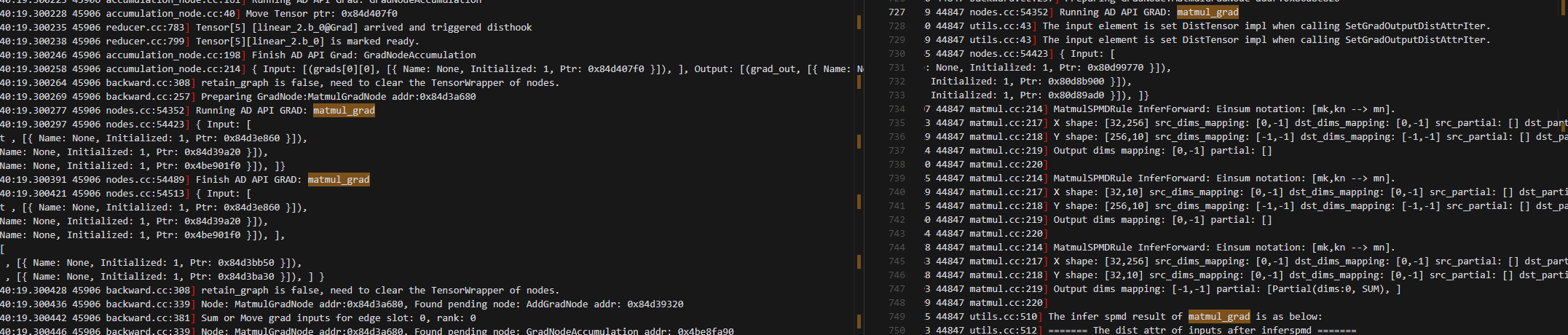
7.动手这里做了allreduce,local_map的动半没做(非local_map的动半也没做)

8.adamw_不同
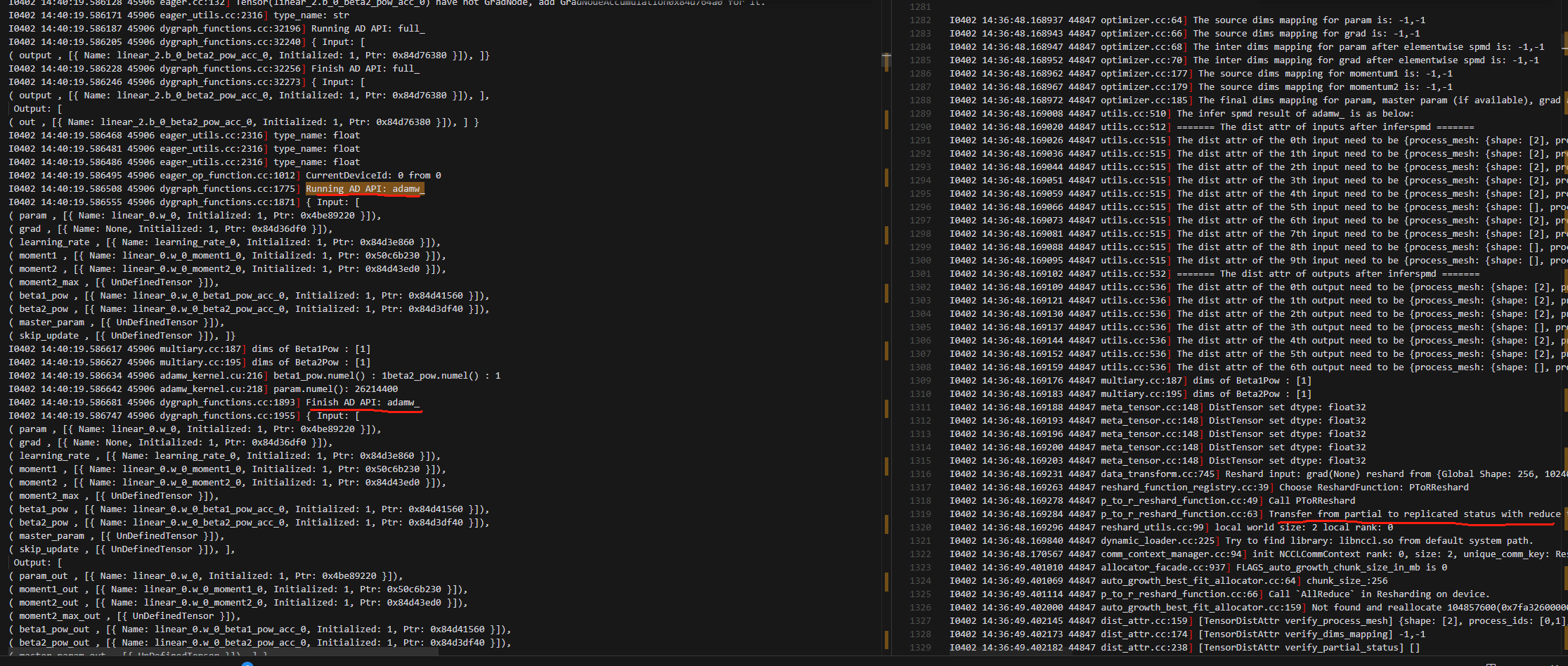
3.结论(纯动半就是不使用local_map的动半)
在forwad过程时:加local_map的动半,进入loss计算前,和纯动半完全相同,进入loss计算时,会多一个dtensor_to_local,进入loss计算后,整个操作和动手完全相同,结束loss计算时,会多一个dtensor_from_local操作,之后又和纯动半完全相同。
在backward过程时:加local_map的动半,会多一个Grad:dtensor_from_local的操作,进入loss后,整个操作grad计算和动手完全相同,结束loss计算的反向后,会多一个Grad:dtensor_to_local操作,之后又和纯动半完全相同。